
KeyError: 'SQLALCHEMY_TRACK_MODIFICATIONS'
sql代码
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
import os
basedir = os.path.abspath(os.path.dirname(__file__))
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI']='sqlite:///'+os.path.join(basedir,'data.sqlite')
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] =True
db = SQLAlchemy(app)
class Role(db.Model):
__tablename__ = 'roles'#__tablename__ 定义在数据库中使用的表名
id = db.Column(db.Integer, primary_key=True)#primary_key如果设为 True ,这列就是表的主键.如果没有定义 __tablename__ ,SQLAlchemy 会使用一个默认名字
name = db.Column(db.String(64), unique=True)
users = db.relationship('User', backref='role')
def __repr__(self):
return '<Role % r>' % self.name
class User(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), unique=True, index=True)
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))
def __repr__(self):
return '<User % r>' % self.username
```主程序代码
from flask import Flask,render_template,url_for,session,redirect,flash
from flask_bootstrap import Bootstrap
from flask.ext.moment import Moment
import os
from flask_sqlalchemy import SQLAlchemy
from flask.ext .wtf import Form
from wtforms import StringField,SubmitField #字段类型类导入 字符串,提交
from wtforms.validators import DataRequired #从表单验证 导入 请求
from datetime import datetime
from sql import db,User,Role,app
class NameForm(Form):
name = StringField('你的名字 ?',validators=[DataRequired()]) #DataRequired()[验证函数]表示数据示为必须非空
submit = SubmitField('提交')
app = Flask(__name__)
app.config['SECRET_KEY'] ='hard to guess string'
bootstrap = Bootstrap(app)
monent = Moment(app)
@app.route('/',methods=['GET','POST']) #app后面的metheds参数告诉Flask 在URL映射中吧视图函数注册为Get Post请求的处理程序.如果没有metheds
#参数,就只把视图函数注册为GET请求的处理程序
def index():
form = NameForm()
if form.validate_on_submit():#如果数据能被所有验证函数接收(上面的)返回True 否则False
user = User.query.filter_by(username = form .name.data).first()
if user is None:
user = User(username = form.name.data )
db.session.add(user)
session['known'] =False
else:
session['known']= True
session['name'] = form.name.data
form .name.data=''
return redirect(url_for('index'))
return render_template('user.html',form = form ,name=session.get('name'),known = session.get('known',False))
@app.errorhandler(404)
def page_not_found(e):
return render_template('404.html'),404
if name == '__main__':
app.run(debug=True)
```一提交表单就错误 图片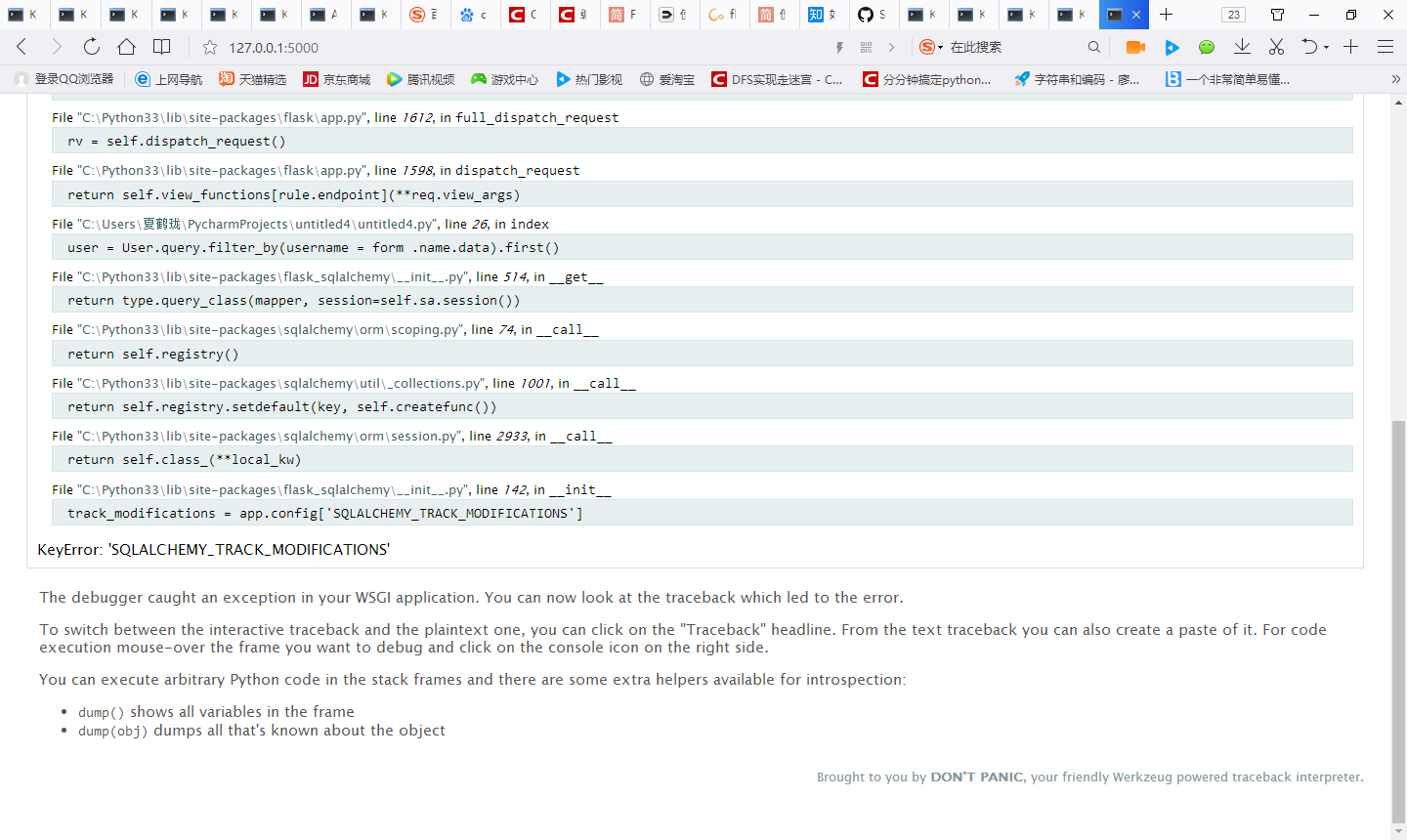图片说明](https://img-ask.csdn.net/upload/201801/12/1515731822_970460.png)




