
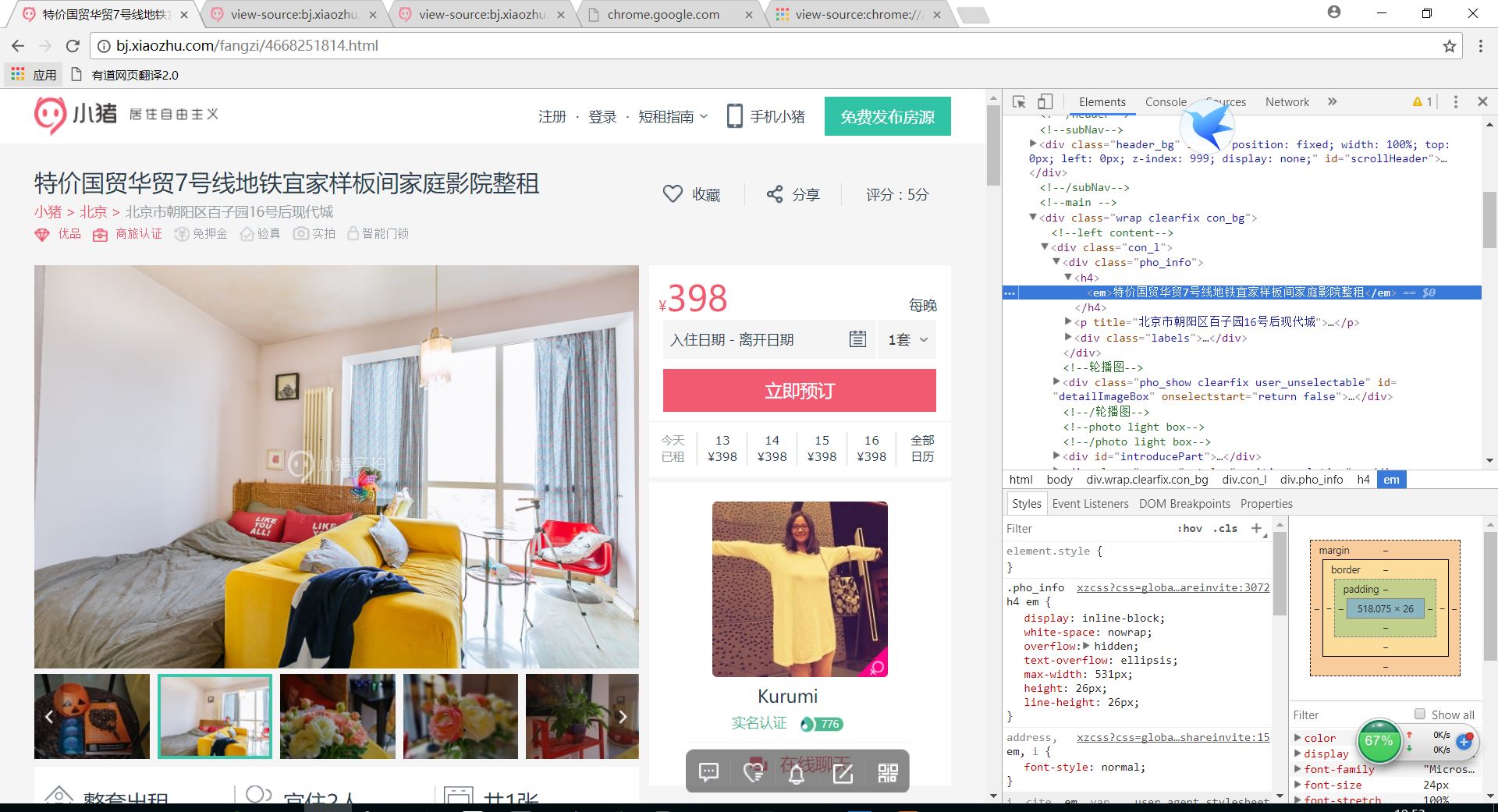
 我想爬小猪租房网北京地区房源前三页 我的爬虫书上用开发者工具的copyselector 爬取
我想爬小猪租房网北京地区房源前三页 我的爬虫书上用开发者工具的copyselector 爬取
请问为什么 我的代码运行不对 什么也不显示 我是大一学生不懂什么具体的html css具体规则
基本点完copyselector 就直接粘贴了 不知道是否还要加工一下
#encoding:utf-8
from bs4 import BeautifulSoup
import requests
import time
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
def get_links(url):
wbdata = requests.get(url, headers=headers)
print(wbdata.status_code)
soup = BeautifulSoup(wbdata.text, 'lxml')
links = soup.select('#page_list > ul > li > a')
for link in links:
href = link.get("href")
get_info(href)
def get_info(url):
wbdata = requests.get(url, headers=headers)
soup = BeautifulSoup(wbdata.text, 'lxml')
tittles = soup.select('div.pho_info > h4')
addresss = soup.select('body > div.wrap.clearfix.con_bg > div.con_l > div.pho_info > p > span')
prices = soup.select('#pricePart > div.day_l > span')
for tittle, address, price in zip(tittles, addresss, prices):
data={'tittle':tittle.get_text().strip(),'address':address.get_text().strip(),'price':price.get_text()}
print(data)
if __name__ == '__main__':
urls = ['http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(number) for number in range(1, 3)]
for ursl in urls:
get_links(ursl)
time.sleep(2)




