
最近买了本爬虫书 他是用chrome 开发者工具的copyselectorr来获取元素地址
我按照书上爬取小猪租房网 比方说我怕取图片上的的地址按照copyselector 粘贴过来的是body > div.wrap.clearfix.con_bg > div.con_l > div.pho_info > p > span 但是程序运行不对输出空白 改成这样就对了'div.con_l > div.pho_info > p > span' 请问这是为什么呢 为什么删掉就行 本人目前大一 水平有限 望各位大佬用尽量简单的知识讲解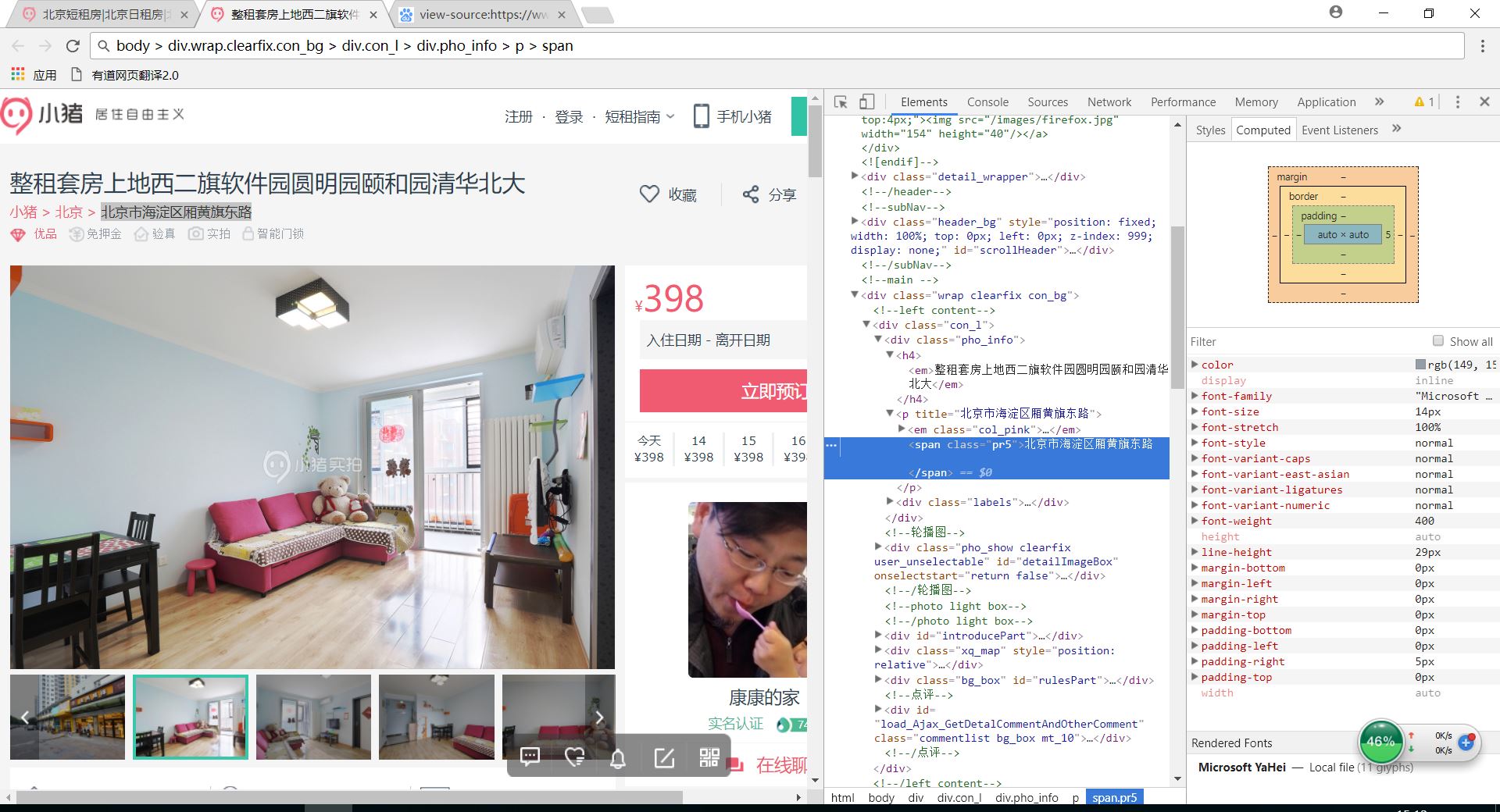 以下是我的代码 问题对应adresss那行
以下是我的代码 问题对应adresss那行
#encoding:utf-8
from bs4 import BeautifulSoup
import requests
import time
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
def get_links(url):
wbdata = requests.get(url, headers=headers)
print(wbdata.status_code)
soup = BeautifulSoup(wbdata.text, 'lxml')
links = soup.select('#page_list > ul > li > a')
for link in links:
href = link.get("href")
get_info(href)
def get_info(url):
wbdata = requests.get(url, headers=headers)
soup = BeautifulSoup(wbdata.text, 'lxml')
tittles = soup.select('div.pho_info > h4')
addresss = soup.select('body > div.wrap.clearfix.con_bg > div.con_l > div.pho_info > p > span')
prices = soup.select('#pricePart > div.day_l > span')
for tittle, address, price in zip(tittles, addresss, prices):
data={'tittle':tittle.get_text().strip(),'address':address.get_text().strip(),'price':price.get_text()}
print(data)
if __name__ == '__main__':
urls = ['http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(number) for number in range(1, 3)]
for ursl in urls:
get_links(ursl)
time.sleep(2)




