
Python2.7版本配置selenium之后,打开火狐驱动的时候提示“无法定位程序输入点 SymFromAddrW 于动态链接库 dbgehelp.dll”。cmd中显示 “selenium.common.exceptions.WebDriverException: Message: Service geckodriver unexpectedly exited. Status code was: -1073741511”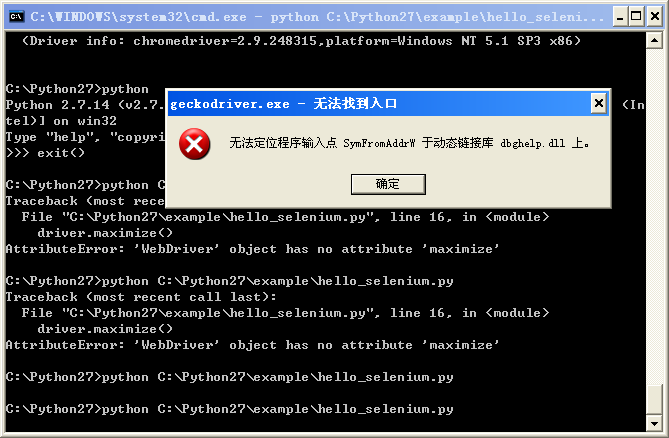
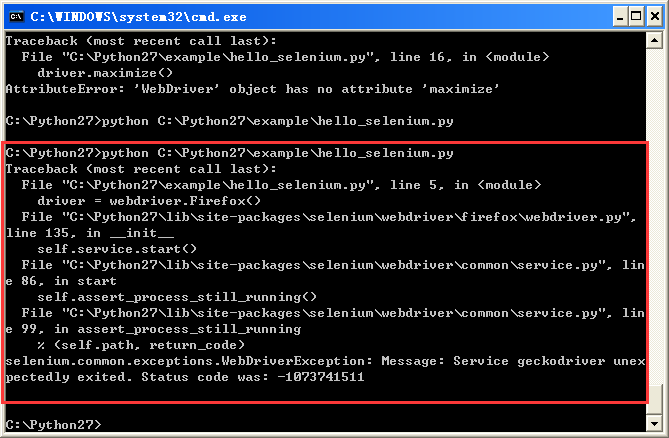
运行代码:
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
print driver.title
driver.close







