最近刚开始学习Lucene, 是按照IK6.5分词保存索引和查询,现在默认查询是按照命
中分数排序,可是还有一个字段是记录浏览次数的,就是当一条记录被浏览的次数多就应该出现在最上面,相当于要对这个字段进行排序,这个可以更新索引,但是查询的时
候怎么样在分数一样的情况下对另一个字段进行排序?
Sort在这里怎么用,用Sort之后就一条也查不出来了,不用就可以正常查询!
SortField sortField = new SortField("checkTimes", SortField.Type.STRING,true);
org.apache.lucene.search.Sort sort = new org.apache.lucene.search.Sort(sortField);
TopDocs topDocs = indexSearcher.search(query, 20, sort);

lucene/IK查询怎么在得分一样的情况下按照另一个字段排序

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答 默认 最新
 GuanfaLi 2018-02-06 03:27关注
GuanfaLi 2018-02-06 03:27关注Lucene的默认排序是按照Document的得分进行排序的。当检索结果集中的两个Document的具有相同的得分时,默认按照Document的ID对结果进行排序。
下面研究几种设置/改变检索结果排序的方法。
1、改变Document的boost(激励因子)
改变boost的大小,会导致Document的得分的改变,从而按照Lucene默认的对检索结果集的排序方式,改变检索结果中Document的排序的提前或者靠后。在计算得分的时候,使用到了boost的值,默认boost的值为1.0,也就说默认情况下Document的得分与boost的无关的。一旦改变了默认的boost的值,也就从Document的得分与boost无关,变为相关了:boost值越大,Document的得分越高。
2、改变Field的boost(激励因子)
改变Field的boost值,和改变Document的boost值是一样的。因为Document的boost是通过添加到Docuemnt中Field体现的,所以改变Field的boost值,可以改变Document的boost值。
3、使用Sort排序工具实现排序
Lucene在查询的时候,可以通过以一个Sort作为参数构造一个检索器IndexSearcher,在构造Sort的时候,指定排序规则。
调用sort进行排序的方法是IndexSearcher.search,例如:
IndexSearcher.search(query,sort);
关于Sort类,在其内部定义了6种构造方法:
public Sort() //
public Sort(SortField field) //通过构造某个域(field)的SortField对象根据一个域进行排序
public Sort(SortField[] fields) //通过构造一组域(field)的SortField对象组实现根据多个域排序
public Sort(String field) //根据某个域(field)的名称构造Sort进行排序
public Sort(String field, boolean reverse) //根据某个域(field)的名称构造SortField进行排序,reverse为true为升序
public Sort(String[] fields) //根据一组域(field)的名称构造一组Sort进行排序
4、直接使用SortField实现排序
关于SortField类,在其内部定义了7种构造方法:
public SortField (String field, boolean reverse)//根据某个域(field)的名称构造SortField, reverse为false为升序
public SortField (String field, int type)
public SortField (String field, int type, boolean reverse)
public SortField (String field, Locale locale)
public SortField (String field, Locale locale, boolean reverse)
public SortField (String field, SortComparatorSource comparator)
public SortField (String field, SortComparatorSource comparator, boolean reverse)
type对应的值分别为:
SortField. SCORE 按积分排序
SortField. DOC 按文档排序
SortField. AUTO 域的值为int、long、float都有效
SortField.STRING 域按STRING排序
SortField..FLOAT
SortField.LONG
SortField.DOUBLE
SortField.SHORT
SortField.CUSTOM 通过比较器排序
SortField.BYTE
5、自定义排序
Lucene中的自定义排序功能和Java集合中的自定义排序的实现方法差不多,都要实现一下比较接口. 在Java中只要实现Comparable接口就可以了.但是在Lucene中要实现SortComparatorSource接口和ScoreDocComparator接口.在了解具体实现方法之前先来看看这两个接口的定义吧解决 无用评论 打赏举报 分享
- 2017-11-24 02:34回答 3 已采纳 用了Lucene 7.1.0,编译环境要求是jdk1.8,Lucene6+都是1.8,后来因为工程需要换成了用了Lucene-5.5.5,这俩版本用起来没啥区别
- 2015-05-02 12:23回答 2 已采纳 make sure the fields have stored=true <field name="field_name" type="text_general" indexed="tr
- 2022-11-27 15:54回答 1 已采纳 你看下这篇博客吧, 应该有用👉 :Lucene+springboot 实现一个简单的搜索
- 2020-12-21 14:37Strive11的博客 最近公司有在用solr作为搜索引擎,然后也了解了一下solr,学习了一些solr相关的知识,并记录下来分享一下。 solr下载地址: https://lucene.apache.org/solr/downloads.html 注意:solr8.6之后不支持数据从数据库...
- 2014-10-19 12:24回答 1 已采纳 建议直接用solr或者es。想精确查找,对应的索引字段应不分词,模糊就分词。
- 2015-05-04 13:58回答 1 已采纳 I found the solution, I put all tickets into one column tickets and I store ticket codes there and
- 2017-07-03 05:19回答 2 已采纳 我猜想分词出现的问题,你可以下个luke去查看分词的情况
- 2019-12-06 16:15奋斗在路上的码农的博客 搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。例如: 百度 谷歌 1.2 `搜索引擎基本的运行原理 ...
- 2010-06-29 10:37回答 1 已采纳 I resolved this problem. Default Zend_Search_Lucene analyzer skips digits. There is a special anal
- 2012-05-05 01:17回答 2 已采纳 I am doing this using the solr-php-client. I do use a regular expression to parse out a specific v
- 2015-08-31 10:01回答 1 已采纳 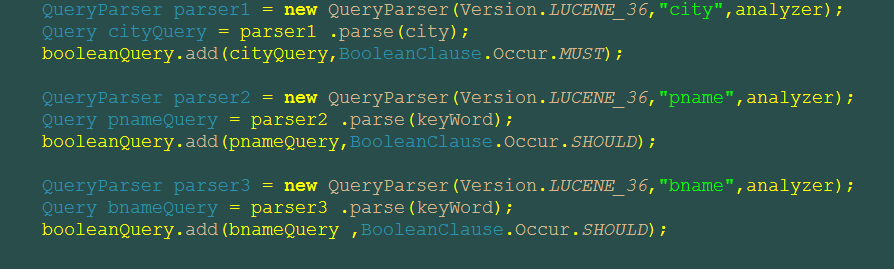 我现在这么写的效果是and es.city=1031
- 2019-10-07 18:15dayou7738的博客 在Lucene4.4中,想要实现搜索结果按照时间倒序的效果:如果两个文档得分相同,那么就按照发布时间倒序排列;否则就按照分数排列。这种效果在Lucene4.6中实现起来极其简单,直接利用search接口的Sort参数即可达成,...
- 2010-08-12 13:56回答 2 已采纳 I've searched google for you : The default boolean operator may be set or retrieved with the Zend
- 2018-09-27 21:29是小方啦的博客 简单的说,搜索就是搜寻、查找,在IT行业中就是指用户输入关键字,通过相应的算法,查询并返回用户所需要的信息。 1.2 普通的数据库搜索 类似:select * from 表名 where 字段名 like ‘%关键字%’ 例如:select ...
- 2021-11-21 21:18coolwei-的博客 Lucene&ElasticSeach&Kafka Lucene&ElasticSeach 1 什么是全文检索 1.1 数据分类 生活中的数据总体分为两种:结构化... 在数据库中搜索很容易实现,通常都是使用 sql语句进行查询,而且能很快的得到查询
- 没有解决我的问题, 去提问

