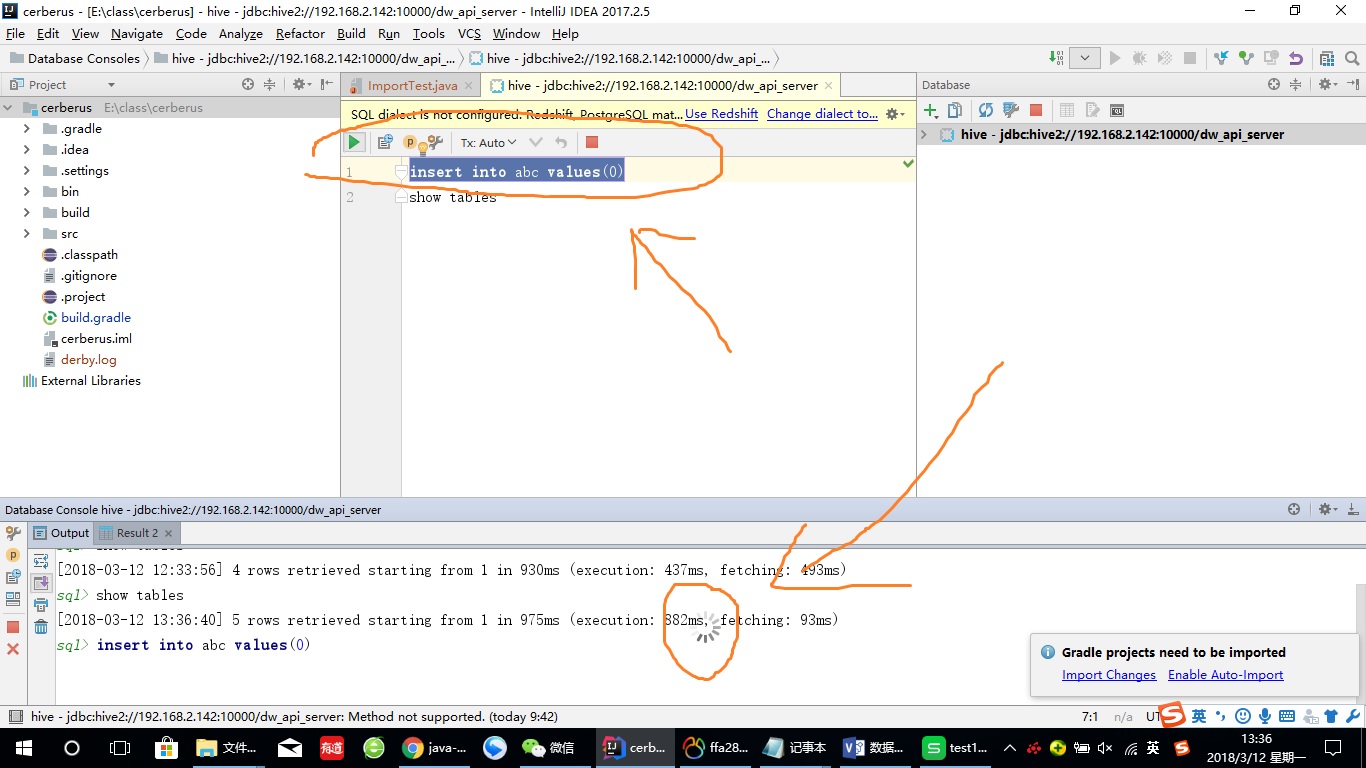
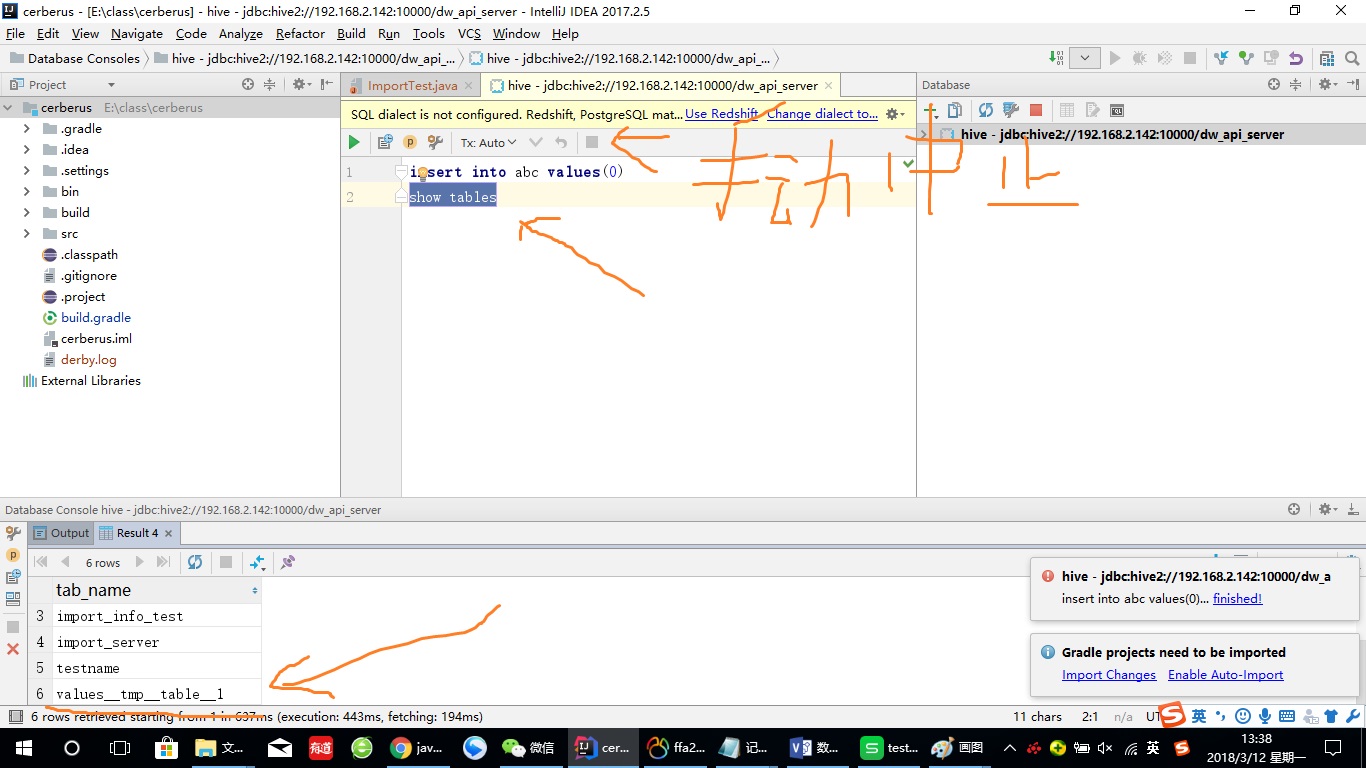
先简单叙述,最近有个项目需要使用hive,目前我的数据在一个map中,我使用jdbc连接hive,连接没有问题,创建表什么的也正常,但是一执行insert into 语句,就会卡住,就是一直转圈,不报错,然后我强行终止后会出现一张临时表,临时表中有我要插入的数据,但是并没有插入我指定的那张表,而且连接关闭重新连接后,临时表就消失了,救救我吧, 是在搞不定hive这个
我的问题类似于这个博主说的http://www.aboutyun.com/thread-20833-1-1.html
但是我不仅这样,我是一执行insert,还会卡主,不往下执行,我用idea的datasource也是这样,必须手动停止,然后就会出现临时表
hive的地址是公司给的地址
请问怎么办,拜托了各位学大数据的大神,已经折磨我一周了