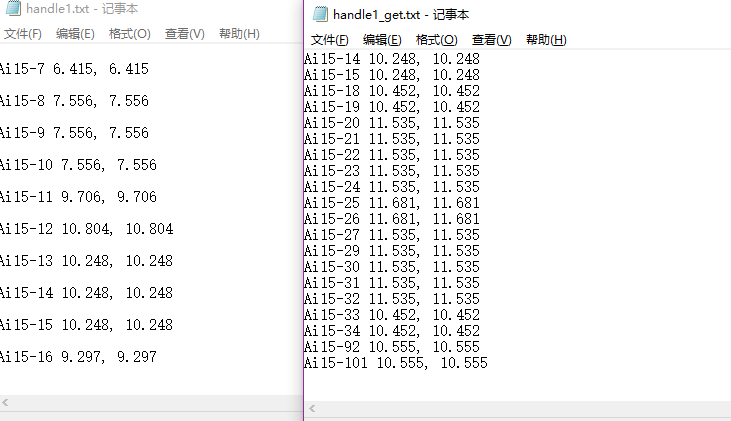
现有TXT文本数据,每个200M左右,近1000个,txt文本内数据格式如下:
Ai15-2 9.531, 9.531
Ai15-3 9.531, 9.531
Ai15-4 9.531, 9.531
Ai15-5 9.531, 9.531
Ai15-6 9.531, 9.531
Ai15-7 6.415, 6.415
Ai15-8 7.556, 7.556
Ai15-9 7.556, 7.556
Ai15-10 7.556, 7.556
Ai15-11 9.706, 9.706
Ai15-12 10.804, 10.804
Ai15-13 10.248, 10.248
Ai15-14 10.248, 10.248
Ai15-15 10.248, 10.248
Ai15-16 9.297, 9.297
Ai15-17 9.297, 9.297
Ai15-18 10.452, 10.452
Ai15-19 10.452, 10.452
Ai15-20 11.535, 11.535
Ai15-21 11.535, 11.535
Ai15-22 11.535, 11.535
Ai15-23 11.535, 11.535
Ai15-24 11.535, 11.535
Ai15-25 11.681, 11.681
Ai15-26 11.681, 11.681
Ai15-27 11.535, 11.535
Ai15-28 12.515, 12.515
Ai15-29 11.535, 11.535
Ai15-30 11.535, 11.535
Ai15-31 11.535, 11.535
Ai15-32 11.535, 11.535
Ai15-33 10.452, 10.452
Ai15-34 10.452, 10.452
Ai15-35 9.297, 9.297
Ai15-36 9.297, 9.297
Ai15-37 9.297, 9.297
Ai15-38 8.521, 8.521
Ai15-39 8.521, 8.521
Ai15-40 5.83, 5.83
Ai15-41 5.83, 5.83
Ai15-42 5.83, 5.83
Ai15-43 5.83, 5.83
Ai15-44 5.753, 5.753
Ai15-45 5.753, 5.753
Ai15-46 3.745, 3.745
Ai15-52 5.995, 5.995
Ai15-53 4.19, 4.19
Ai15-63 6.237, 6.237
Ai15-64 3.846, 3.846
Ai15-73 5.919, 5.919
Ai15-74 7.351, 7.351
Ai15-84 9.18, 9.18
Ai15-91 9.355, 9.355
Ai15-92 10.555, 10.555
Ai15-100 6.097, 6.097
Ai15-101 10.555, 10.555
Ai15-112 9.355, 9.355
Ai15-122 6.097, 6.097
Ai15-127 8.521, 8.521
......
数据中每行含有的数据结构为:
">"+"序号名"+"空格"+"数字"+","+"空格"+"数字"
想用一段python程序,
将数据内数字大小在9.500到12.500之间的行保留,
将数据内数字小于9.500和大于12.500的行删除,
比如,上面的数据,
删除行内"数字"小于"9.500"的行,和行内"数字"大于"12.500"的行后,
剩下的数据为:
Ai15-2 9.531, 9.531
Ai15-3 9.531, 9.531
Ai15-4 9.531, 9.531
Ai15-5 9.531, 9.531
Ai15-6 9.531, 9.531
Ai15-11 9.706, 9.706
Ai15-12 10.804, 10.804
Ai15-13 10.248, 10.248
Ai15-14 10.248, 10.248
Ai15-15 10.248, 10.248
Ai15-18 10.452, 10.452
Ai15-19 10.452, 10.452
Ai15-20 11.535, 11.535
Ai15-21 11.535, 11.535
Ai15-22 11.535, 11.535
Ai15-23 11.535, 11.535
Ai15-24 11.535, 11.535
Ai15-25 11.681, 11.681
Ai15-26 11.681, 11.681
Ai15-27 11.535, 11.535
Ai15-29 11.535, 11.535
Ai15-30 11.535, 11.535
Ai15-31 11.535, 11.535
Ai15-32 11.535, 11.535
Ai15-33 10.452, 10.452
Ai15-34 10.452, 10.452
Ai15-92 10.555, 10.555
Ai15-101 10.555, 10.555
......
最好可以在原来的TXT文件内直接操作;
也可以将删除之后留下的数据存放在新的文件中。