


10条回答 默认 最新
 红帽01 2018-03-19 04:26关注
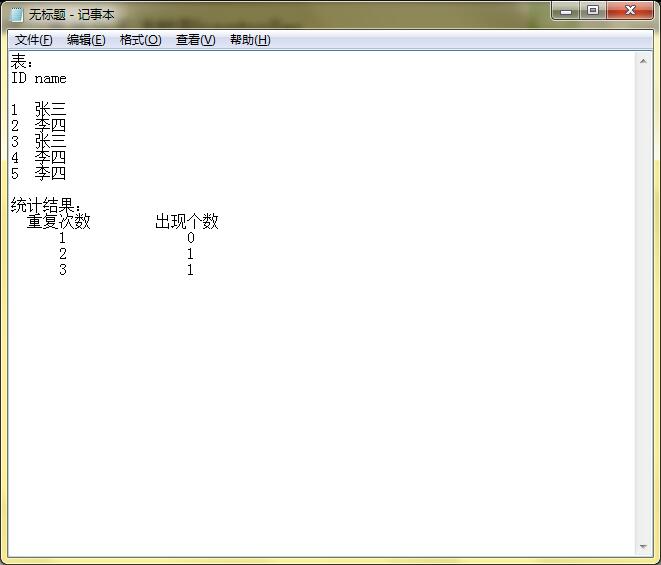
红帽01 2018-03-19 04:26关注SELECT * FROM ( SELECT counts , COUNT(*) counts2 FROM ( SELECT name , COUNT(*) AS counts FROM talbe*** GROUP BY name ) a GROUP BY counts ) a ORDER BY counts本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
分享
- 2024-10-08 15:18初九之潜龙勿用的博客 比如我们有一组题库数据,主要包括题目和选项字段(如单选题目、多选题目和判断题目),一个合理的数据存储应该至少保证这些题目在分类中不应该出现重复题目标题数据,本文将介绍如何利用group by 、with rollup、...
- 2020-12-16 05:40在MySQL数据库管理中,有时我们需要清理表中的重复数据,但同时希望保留每个唯一标识符(如`peopleName`)下的最小`peopleId`。这里提到的解决方案是通过使用子查询来实现这一目标,但该过程可能会遇到一些挑战。...
- 2022-10-05 11:53小满大王i的博客 已解决SQL分组去重并合并相同数据
- 2025-09-20 17:37AI量化价值投资入门到精通的博客 你有没有遇到过这样的场景?写了一条看似简单的SQL,跑了10分钟还没出结果;或者明明只查几列数据,却要扫描整个100GB的表;...最终,让你的SQL从“泥地开车”变成“高速巡航”,查询效率提升10倍甚至100倍。
- 2025-05-05 20:40光子AI的博客 本文聚焦大数据ETL场景下的数据编排技术,涵盖任务依赖建模、调度策略设计、异常处理机制、性能优化等核心议题,结合工业级案例剖析最佳实践,帮助读者构建可扩展、高可靠的ETL工作流。核心概念:定义数据编排,解析...
- 2025-06-14 17:31庄小焱的博客 数据建模设计是数据治理体系中的关键组成,承载着数据标准化、资产化与高质量使用的核心目标。本文从治理视角出发,深入探讨数据建模在保障企业数据一致性、复用性和共享性方面的重要作用。文章首先梳理了建模的三层...
- 2020-12-16 01:06总的来说,处理MySQL表中的重复数据需要对SQL查询有深入的理解,包括分组、聚合函数、子查询以及事务和锁定机制。通过合理的SQL语句,我们可以有效地查找并删除重复数据,保持数据的整洁性和一致性。在实际应用中,...
- 2024-11-05 22:43志启计算机编程的博客 根据自己对一些大数据分析相关文章的一些阅读和理解,整理了一些数据分析、Sparksql(也可以是hivesql)常见高级技巧的使用示例,包括语句的实现和特定场景优化等。这些示例有些是大厂数据开发面试中的常见题目。
- 2025-04-26 21:49光子AI的博客 金融行业的数字化转型已进入深水区,日均产生的数据量从TB级跃升至PB...本文聚焦大数据架构在金融数据分析中的应用如何设计高扩展性的金融数据存储架构?如何实现毫秒级实时金融数据分析?如何平衡数据治理与分析效率?
- 2022-03-20 16:00ZoraAvo的博客 一、观测——通过技术手段获取数据,并对数据进行分析和测量,即获取数据制作报表、图表、仪表盘 观察:采集、储存、展示数据 【采集数据】 1.解析系统日志 2.埋点 3.通过传感器采集 4.爬虫 解析别人的...
- 没有解决我的问题, 去提问

