就是网上运行爬虫这一步一直有问题,求解!
命令:curl http://localhost:6800/schedule.json -d project=robot -d spider=s1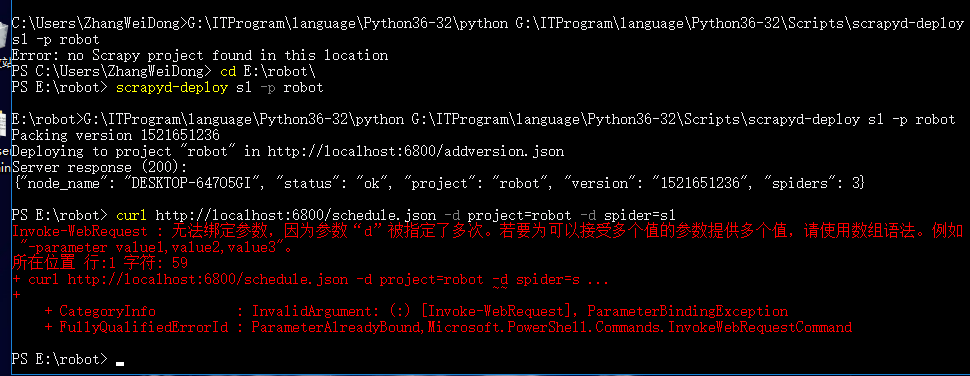

scrapyd 运行爬虫失败,求解!!!!

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答 默认 最新

- 2022-06-10 17:09回答 4 已采纳 1、为什么只能爬到猫猫类的?这个跟你输入label1 = str(input("输入指定的类型:"))这句有关,虽然你后边a1 = list(label1)给它定义成列表,但转成列表后就不是你想要的意
- 2022-04-09 22:19回答 2 已采纳 用pypy,namba(需重构,加装饰器),cython(需重构,显式声明类型)用正则表达式更快,但适用性会降低灵活运用异步减少中间值的使用少用for循环控制线程数量,考虑协程、多进程,因为有GIL的
- 2015-08-17 15:37回答 4 已采纳 难度不大,中专生也能做,问题是代码量大,因为C++类库不全,语法繁琐,还容易出错。推荐用C# Java一类的语言。 特别是多线程、字符串解析、集合排序筛选等等这些常见的任务,用C++写起来很麻烦。
- 2018-10-26 21:44魔都飘雪的博客 昨天的时候我参加了掘金组织的一场 Python 网络爬虫主题的分享活动,主要以直播的形式分享了我从事网络爬虫相关研究以来的一些经验总结,整个直播从昨天下午 1 点一直持续到下午 5 点,整整四个小时。 整个分享分为...
- 2021-10-26 18:01回答 2 已采纳 是因为xpath没有写正确,试试:img_src = tree.xpath('//*[@id="app"]/div[3]/div/div[2]/div/div[2]/a[3]/img/@src')[0
- 2021-11-19 23:19回答 1 已采纳 re.findall(findChara, str(item)) 没有匹配到,返回的是空列表[] print(str(item)) 输出 没有<h3></h3>标签 你题目
- 2023-04-03 11:12回答 3 已采纳 from selenium import webdriver from lxml import etree driver = webdriver.Edge() url='https://so.szl
- 2020-05-13 16:11pengjunlee的博客 scrapyd 是由scrapy 官方提供的爬虫管理工具,使用它我们可以非常方便地上传、控制爬虫并且查看运行日志。 参考官方文档:http://scrapyd.readthedocs.org/en/latest/api.html 使用scrapyd 和我们直接运行scrapy ...
- 2021-11-11 20:33回答 2 已采纳 headers要添加cookie信息,看题主的代码加错内容(set-cookie是设置cookie用的)了,加到响应头的了,应该将请求头的cookie信息加上 改下面这样就可以了 import re
- 2022-04-29 11:12回答 1 已采纳 我给你改了一下,你对比看看吧: from bs4 import BeautifulSoup import pandas as pd import requests def crawer_travel
- 2023-04-13 13:18回答 1 已采纳 爬虫严格来讲并不算一个大方向,更偏向于js逆向,python的话推荐走后端方向至于系统学习的话,推荐去blibili找一些路线,然后根据路线去找bilibili上播放量比较高的视频进行系统学习
- 2018-11-25 14:40dream_uping的博客 yield关键字,33关键字之一! yield<- ->生成器 源源不断生成数据的生成器! 实例: 我的尝试: 为何用生成器: 优点如下: 更加节省存储空间 响应更加迅速 使用更加灵活 ......
- 2022-02-13 17:30回答 2 已采纳 url_info.xpath('div[2]/a/@href')返回的列表,要part_link[0]获取列表的第一个元素 part_link_s=str(part_link[0]) 而且你 url
- 2019-04-17 18:11传而习乎的博客 Scrapyd部署爬虫项目 博客目的:本博客介绍了如何安装和配置Scrapyd,以部署和运行Scrapy spider。 Scrapyd简介: Scrapyd是一个部署和运行Scrapy spider的应用程序。它使您能够使用JSON API部署(上载)项目并控制...
- 2021-06-29 08:39冰 河的博客 半小时实现Java网络爬虫,附完整源码,冰河强烈建议收藏!!
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 三菱伺服电机按启动按钮有使能但不动作
- ¥20 为什么我写出来的绘图程序是这样的,有没有lao哥改一下
- ¥15 js,页面2返回页面1时定位进入的设备
- ¥200 关于#c++#的问题,请各位专家解答!网站的邀请码
- ¥50 导入文件到网吧的电脑并且在重启之后不会被恢复
- ¥15 (希望可以解决问题)ma和mb文件无法正常打开,打开后是空白,但是有正常内存占用,但可以在打开Maya应用程序后打开场景ma和mb格式。
- ¥20 ML307A在使用AT命令连接EMQX平台的MQTT时被拒绝
- ¥20 腾讯企业邮箱邮件可以恢复么
- ¥15 有人知道怎么将自己的迁移策略布到edgecloudsim上使用吗?
- ¥15 错误 LNK2001 无法解析的外部符号