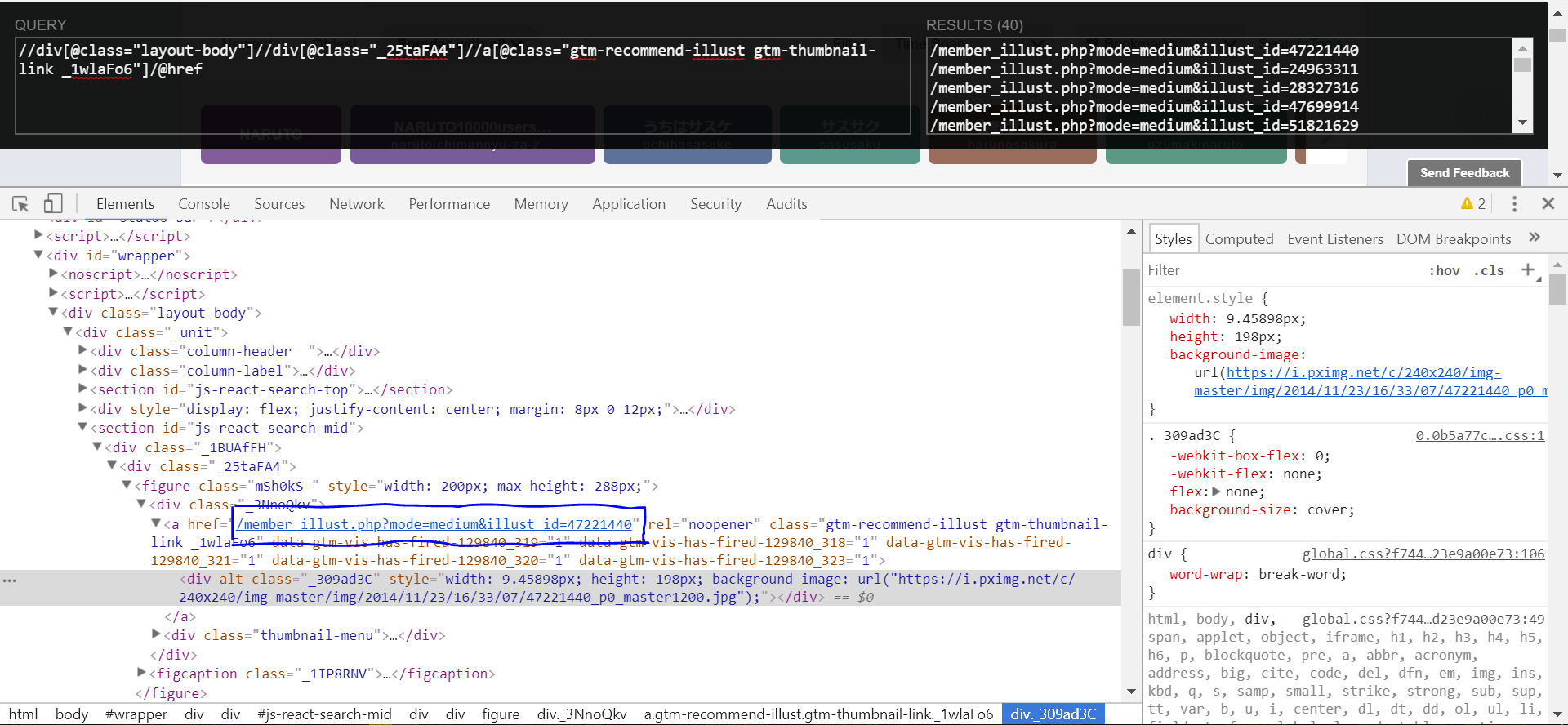
我发现F12查看到的和右键查看到的源代码不一样,Python里返回的是右键查看到的。我该怎么做才能提取到我想要的“/member_illust.php?mode=medium&illust_id=47221440”?
# 获取返回页面数值
page_html = requests.get(html, headers=headers)
# 将html的div 转化为 xml
xmlcontent = etree.HTML(page_html.text)
# 解析HTML文档为HTML DOM模型
# 返回所有匹配成功的列表集合
link_list = xmlcontent.xpath('//div[@class="layout-body"]//div[@class="_25taFA4"]//a[@class="gtm-recommend-illust gtm-thumbnail-link _1wlaFo6"]/@href')
# 直接提取第一个href
for link in link_list:
print(link)

Pixiv.net上通过XPath Helper可以准确获取到想要的,在Python里却无法获取到

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


3条回答

- 2020-09-18 10:38回答 1 已采纳 https://blog.csdn.net/sun_977759/article/details/100989829
- 2021-08-31 18:59回答 2 已采纳 看一下你的代码里header中的cookie值是否有问题,横杠“-”与字符串之间不应该有空格的,改一下,最好是F12查看链接接口的请求头,请求方法和请求参数,要写正确。
- 2016-12-22 13:06回答 2 已采纳 有时间把源码发过来,应该是图片盒子设置width:100%就行了,这个不确定哪出了毛病,不过问题不大
- 2023-12-18 19:46通过爬取网页图片解析pixiv请求等操作爬取图片 使用时注意将{个人Uid}换成自己的uid def Start(): threads = [] threads_id = 1 for _ in range(num_threads): with gLock: work,c_turn = get_job() pass ...
- 2022-04-02 01:26回答 4 已采纳 连接不上数据库。项目中导了数据库驱动包吗?
- 2021-03-17 17:03本程序仅能保证在本人的相关配置环境,网络环境下正常运行。 Anaconda 1.10.0 with Python 3.8, Visual Studio Code Debugee Firefox 83.0, automated with Selenium 3.141.0 关于网络环境问题:墙内,一定需求VPN...
- 2021-03-16 10:51YH_Kaiheila_Bot一款基于Python的P站日榜爬取与下载软件本软件...连接Mysql保证你的网络能够正常连接P站运行Get_pixiv_day_list.py检查数据库,发现信息填充完毕后运行down_img.py图片将自动生成在img文件夹由YH供电
- 2021-05-02 17:51Pxer | 该工具用于 ,由纯clint javascript编写,PV达到10k...转到项目目录并运行npm install以获取安装依赖性 运行npm run dev 在TamperMonkey中添加“ src / local.user.js” 打开一些网页,您将看到运行结果 执照
- 2021-05-08 16:02自述文件 Pixiv到背景 感谢 ,该项目使用其API将受欢迎程度排序的图片抓取到您的桌面背景。 如何使用?... 您可以轻松地在config.py更改一些配置,也可以直接修改代码。 我认为您可以轻松理解代码。
- 2022-04-12 19:35资源分类:Python库 所属语言:Python 资源全名:pixiv_crawler-0.0.4.tar.gz 资源来源:官方 安装方法:https://lanzao.blog.csdn.net/article/details/101784059
- 2022-05-20 10:31资源分类:Python库 所属语言:Python 资源全名:pixiv-tag-analyzer-0.2.tar.gz 资源来源:官方 安装方法:https://lanzao.blog.csdn.net/article/details/101784059
- 2021-05-25 23:17一个基于Python3和Qt的Pixiv友好的GUI下载器 演示版 安装 安装 安装 安装以下库和依赖项 对于Fedora / CentOS: $ sudo yum update $ sudo yum install python3-lxml ImageMagick-devel $ sudo pip3 install ...
- 2021-12-20 23:04EastMage的博客 自从接触python以后就想着爬pixiv,之前因为梯子有点问题就一直搁置,最近换了个梯子就迫不及待试了下。 爬虫无非request获取html页面然后用正则表达式或者beautifulsoup之类现成工具截取我们想要的页面,pixiv也不...
- 2021-05-01 22:39pixiv downloader由于 Pixiv 已不再支持客户端的登录 API,请更新到 v2.12.0 及以后的版本以使用新的登录方式(详见下文)本项目因本人不再使用且摸了而进入仅维护状态,暂不考虑任何非必要的 Feature Request简单写...
- 2021-05-08 00:03适用于Python 3的Async Pixiv API(支持Auth) PixivPy-Async是Pixiv API的异步Python 3库(支持Auth)。 资料来源: : 基于PixivPy: : 笔记 您可能需要使用日语IP(无论是本地IP)来访问Pixiv API。 来自其他...
- 2019-09-16 18:01Pingabc123的博客 在公共函数模块实现获取token函数,方便测试用例代码实现时直接调用拿到token值。 1、使用的模块 requests:第三方模块,用来发送http请求和获取返回的结果。 2、使用的方法 (1)requests的带参数get请求 requests....
- 2024-02-16 21:58SRestia的博客 pixiv的爬取有很多大佬做过了,不过我看了一些都是弄得类似于项目一样,确实都很厉害,但我的需求简单,写在一个文件里适合我这种懒蛋。 1. 首先通过`RankingCrawler`类的`get_multi_page_json`方法,获取榜单的...
- 2020-11-01 15:42Xavier Jiezou的博客 如果我们通过爬虫技术得到了pixiv网站图片的url,那么如何根据url下载图片到本地。 安装模块 pip install requests 测试样例 https://i.pximg.net/img-original/img/2019/11/22/00/00/13/77926406_p0.jpg 下载...
- 2021-05-02 15:53pixiv-app-api 基于承诺的pixiv API客户端 受启发 。 特征 基于承诺 将输出的json键转换为camelCase 将参数转换为snakeCase 支持无需登录的API 安装 $ npm install --save pixiv-app-api 用法 import ...
- 2024-02-28 20:41Python基于botoy和OPQBot的色图机器人.zip 功能 发色图 ~~原神模拟抽卡~~ 自动解析Pixiv画廊链接 ~~B站小程序转换成链接~~ ~~搜图(saucenao)~~ 系统信息
- 没有解决我的问题, 去提问



悬赏问题
- ¥15 怀疑手机被监控,请问怎么解决和防止
- ¥15 Qt下使用tcp获取数据的详细操作
- ¥15 idea右下角设置编码是灰色的
- ¥15 全志H618ROM新增分区
- ¥15 在grasshopper里DrawViewportWires更改预览后,禁用电池仍然显示
- ¥15 NAO机器人的录音程序保存问题
- ¥15 C#读写EXCEL文件,不同编译
- ¥15 MapReduce结果输出到HBase,一直连接不上MySQL
- ¥15 扩散模型sd.webui使用时报错“Nonetype”
- ¥15 stm32流水灯+呼吸灯+外部中断按键