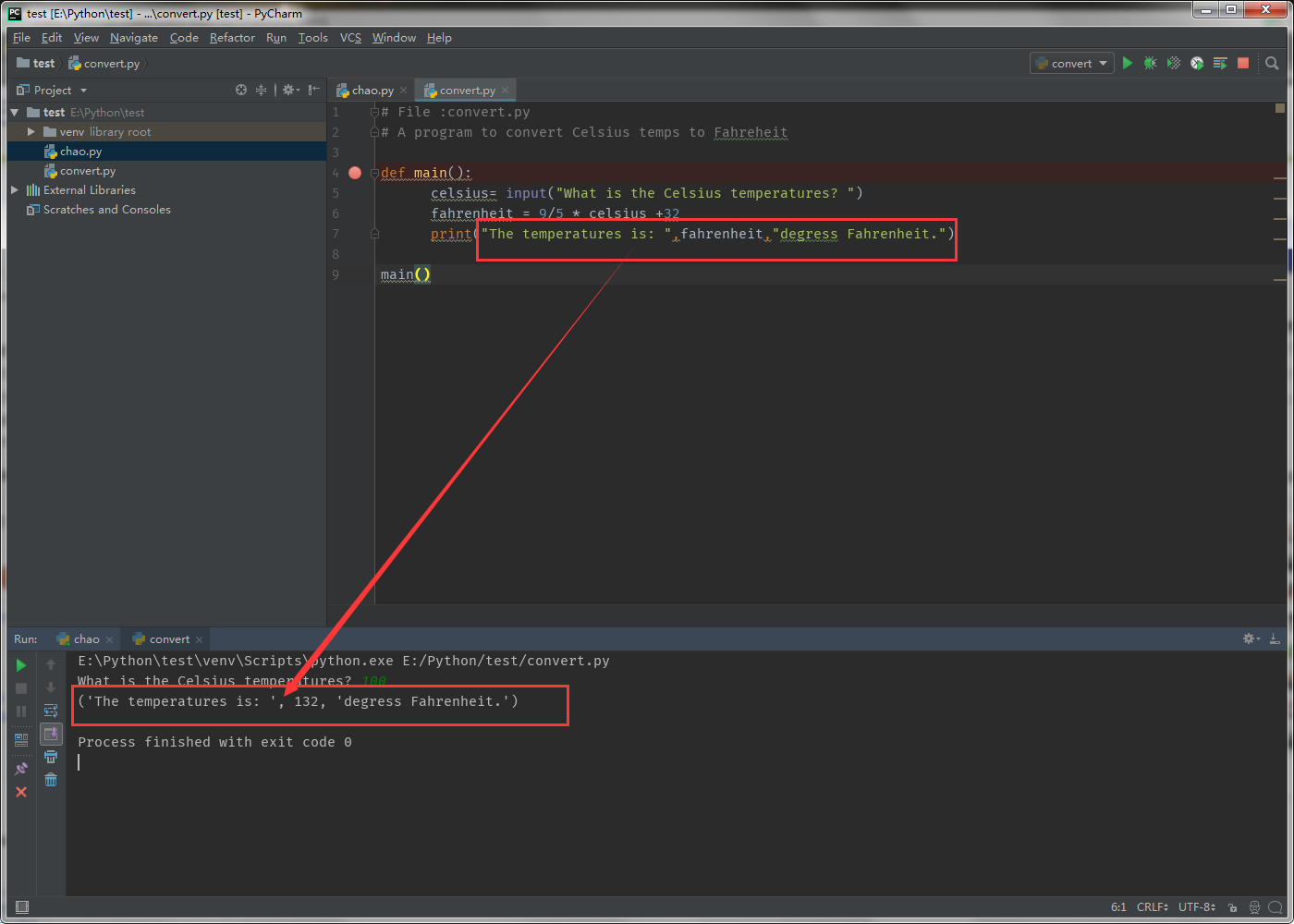

提问大神,python3使用print输出双引号的文本,为什么会显示单引号,逗号也显示出来

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


12条回答 默认 最新

- 2021-05-12 21:11回答 2 已采纳 换行 理解没错 也没其他作用了
- 2018-12-17 07:32回答 10 已采纳 ←如果以下回答对你有帮助,请点击右边的向上箭头及采纳下答案 ``` a=3 print ("'%s'"%(a)) ##方法1 %s为格式化字符串,然后将a传递进去,就变成了'3' prin
- 回答 1 已采纳 假设你的text 元素叫做elem ``` print(''.join([x.strip() for x in elem.itertext() if x.strip()])) ```
- 2023-01-30 12:05微小冷的博客 从新手到高手,从菜鸟到大神,精选90行代码,来看看你能看懂多少行?
- 2021-03-30 20:26回答 5 已采纳 # 外层循环 i 从2循环到99 i = 2 while(i < 100): # 内层循环 j 从2循环到根号 i j = 2 while(j <= (i/j)): #
- 2018-11-26 11:34回答 4 已采纳 因为你只是写了函数,没有运行你的函数啊,删掉plt.show()这句错误语法,在最后一行加入line_plots('test')就可以了 ``` import plotly.plotl
- 2019-04-28 09:17回答 2 已采纳 waveData = np.frombuffer(strData, dtype='int16')
- 2022-09-24 18:22浅墨入画,岁月入禅的博客 python进阶
- 2018-12-23 15:52回答 1 已采纳 应该是你的环境不一致, 你直接在终端上试试import gevent行不行,如果不行 ``` import sys print(sys.path) ``` 打印下你的python路径是
- 2016-12-20 04:17回答 2 已采纳 http://blog.csdn.net/kinglearnjava/article/details/49107253
- 2015-10-24 11:00回答 3 已采纳 是先输出第一个print(s)的;比如当i==3时,第一个prnt(s)调用3次,然后第二个输出,结果为:初始化...
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 怎么获取下面的: glove_word2id.json和 glove_numpy.npy 这两个文件
- ¥15 js调用html页面需要隐藏某个按钮
- ¥15 ads仿真结果在圆图上是怎么读数的
- ¥20 Cotex M3的调试和程序执行方式是什么样的?
- ¥20 java项目连接sqlserver时报ssl相关错误
- ¥15 一道python难题3
- ¥15 牛顿斯科特系数表表示
- ¥15 arduino 步进电机
- ¥20 程序进入HardFault_Handler
- ¥15 oracle集群安装出bug