现在我有一组数据,第一列是入站口到出站口(OD),第二列是刷卡的卡号,第三列是出行总时间。
现在我想研究在相同的OD下,出行时长的分布,并从中筛选出出行时长异常的卡号,默认出行时长超过该OD最短出行时长2倍为异常。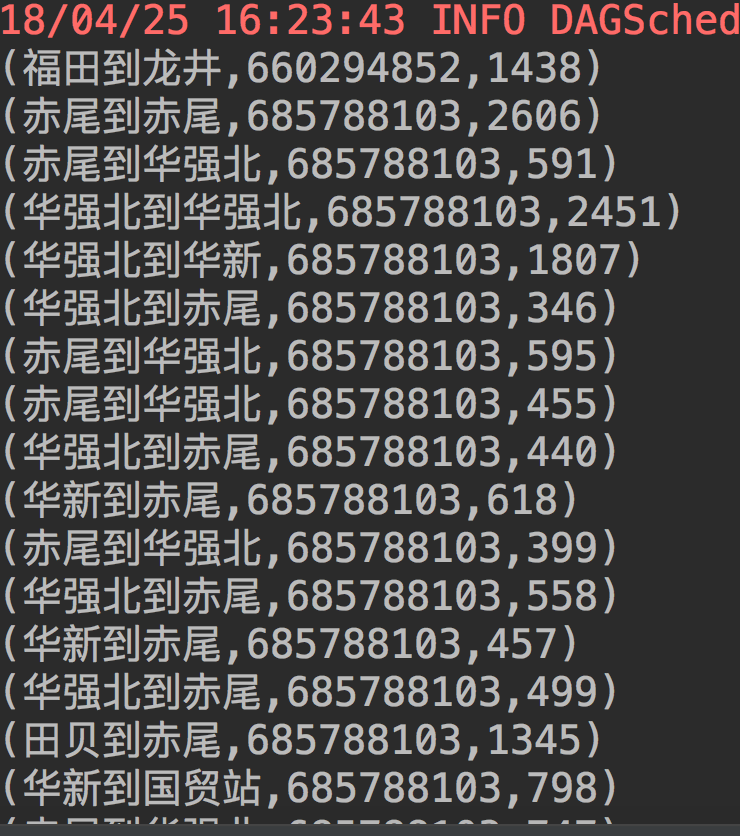

还是昨天的Spark数据分析的问题,求代码,有帮助的可以再加C币

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答 默认 最新
- 默默悟问 2018-04-27 07:18关注
from __future__ import print_function import sys from pyspark.sql import SparkSession def min(a,b): return a if a < b else b if __name__ == "__main__": if len(sys.argv) != 2: print("Usage: odcount <file>", file=sys.stderr) exit(-1) spark = SparkSession\ .builder\ .appName("PythonODCount")\ .getOrCreate() lines = spark.read.text(sys.argv[1]).rdd.map(lambda r: r[0]) lines = lines.filter( lambda line: len(line.strip()) > 0 ) mintimes = lines.flatMap(lambda x: [x[1:-1]]) \ .map( lambda x: (x.split(',')[0], int(x.split(',')[2])) ) \ .reduceByKey(min) mintime_list = mintimes.collect() mintime_map = {} print("min time:") for (od, mintime) in mintime_list: mintime_map[od] = mintime print("%s: %i" % (od.encode('utf-8'), mintime)) largelines = lines.flatMap(lambda x: [x[1:-1]]) \ .filter( lambda x: int(x.split(',')[2]) > 2 * mintime_map.get(x.split(',')[0]) ) print("large time line:") for line in largelines.collect(): print("%s" % line.encode('utf-8')) spark.stop()本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2018-04-26 01:37回答 2 已采纳 ``` from __future__ import print_function import sys from pyspark.sql import SparkSession
- 2023-01-17 22:05回答 2 已采纳 这是一个连接Doris服务器失败的错误,具体原因可能是Doris服务器无法连接或网络故障导致的。
- 2022-01-18 20:31回答 3 已采纳 spark sql中可以使用except来获得两组数据的交集 SELECT * FROM student_1 EXCEPT SELECT * FROM student_2; 你如果是某一行中的某
- 2023-01-02 12:20木子一个Lee的博客 数据规模达到2412个城市,57888条数据,有部分城市部分时间点数据存在缺失或异常。特别说明:实验所用数据均为网上爬取,没有得到中央气象台官方授权使用,使用范围仅限本次实验使用,请勿用于商业用途。
- 2022-06-23 13:55回答 1 已采纳 Hadoop和Spark都是处理大数据的框架。就象你说关系型数据库,这只是一个概念,但是代表了一系列的含意,比如数据是结构化的,基于关系模型存储的。而MySQL、Oracle、SqlServer这些就
- 2022-01-25 09:53回答 1 已采纳 问题已解决:参考这个=====>https://blog.csdn.net/weixin_43753599/article/details/122697542?spm=1001.2014.300
- 2022-12-15 15:54
 Spark 读取 Hive 数据报错 NoSuchMethodError : org.apache.spark.sql.catalyst.catalog.SessionCatalog
hive
spark
大数据
回答 1 已采纳 22/12/15 15:32:44 INFO SparkContext: Invoking stop() from shutdown hook集群资源不足,且动态资源分配申请的executors、内存
Spark 读取 Hive 数据报错 NoSuchMethodError : org.apache.spark.sql.catalyst.catalog.SessionCatalog
hive
spark
大数据
回答 1 已采纳 22/12/15 15:32:44 INFO SparkContext: Invoking stop() from shutdown hook集群资源不足,且动态资源分配申请的executors、内存 - 2022-07-23 12:00风度78的博客 当我们每天面对扑面而来的海量数据时,是战斗还是退却,是去挖掘其中蕴含的无限资源,还是让它们自生自灭?我们的答案是:“一切都取决于你自己”。对于海量而庞大的数据来说,在不同人眼里,既可以是一座亟待销毁的...
- 2017-11-07 09:17回答 3 已采纳 我觉得你有点大材小用了,,而且太麻烦了,, 首先,spark有原生的sparkSQL可以直接调用,没必要hive 我觉得你对大数据的计算框架没理解透彻, spark和hadoop都是一样的,计算
- 2022-11-29 13:16回答 1 已采纳 1、目前pyspark.sql.types支持的数据类型:NullType、StringType、BinaryType、BooleanType、DateType、TimestampType、Decim
- 2022-08-27 16:48回答 1 已采纳 webui上能看到各个stage运行的阶段,在哪个节点上执行的以及执行信息,希望能帮到你
- 2023-05-31 11:34小明爱學習的博客 2020年美国新冠肺炎疫情...本篇论文旨在使用 Spark 进行数据处理分析,以了解2020年美国新冠肺炎疫情在该国的传播情况,并探讨各州疫情数据之间的相互关系。在数据处理和可视化方面采用 Spark 和 Python 技术进行实现。
- 2021-07-16 16:19回答 1 已采纳 唯一标识为ID第一个思路为:数据都装入两个map中。key为id value为值。json1为map1,json2为map2。id装为两个数组.json1为数组1,json2为数组2。 新增的 就是j
- B站计算机毕业设计超人的博客 目前市面上Python+Spark的爬虫招聘数据分析可视化系统很少,于是我们设计了一套,希望给大家一套完整的设计方案和思路,助力大数据开发!
- 2023-09-04 08:09想你依然心痛的博客 文章目录 1.3 Scala的数据结构 1.3.1 数组 数组的遍历 数组转换 1.3.2 元组 创建元组 获取元组中的值 拉链操作 1.3.3 集合 List Set Map 1.3 Scala的数据结构 对于每一门编程语言来说,数组(Array)都是重要的数据...
- 没有解决我的问题, 去提问

悬赏问题
- ¥25 由IPR导致的DRIVER_POWER_STATE_FAILURE蓝屏
- ¥50 有数据,怎么建立模型求影响全要素生产率的因素
- ¥50 有数据,怎么用matlab求全要素生产率
- ¥15 TI的insta-spin例程
- ¥15 完成下列问题完成下列问题
- ¥15 C#算法问题, 不知道怎么处理这个数据的转换
- ¥15 YoloV5 第三方库的版本对照问题
- ¥15 请完成下列相关问题!
- ¥15 drone 推送镜像时候 purge: true 推送完毕后没有删除对应的镜像,手动拷贝到服务器执行结果正确在样才能让指令自动执行成功删除对应镜像,如何解决?
- ¥15 求daily translation(DT)偏差订正方法的代码