select id,taskCode,taskSign,riskCode,classCode,policyCodes,createTime,updatTime from f_policytask
导入之后查询出数据的字段变成了小写,我建索引的时候写的是驼峰,所以模糊查询的时候查询不出来。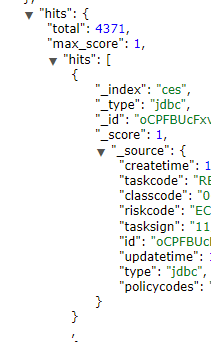
(目前有个解决办法是把驼峰改成下划线,但是java里面写的很别扭,有没有其他的解决办法?谢谢大家)

select id,taskCode,taskSign,riskCode,classCode,policyCodes,createTime,updatTime from f_policytask
导入之后查询出数据的字段变成了小写,我建索引的时候写的是驼峰,所以模糊查询的时候查询不出来。
(目前有个解决办法是把驼峰改成下划线,但是java里面写的很别扭,有没有其他的解决办法?谢谢大家)
 分享
分享
