
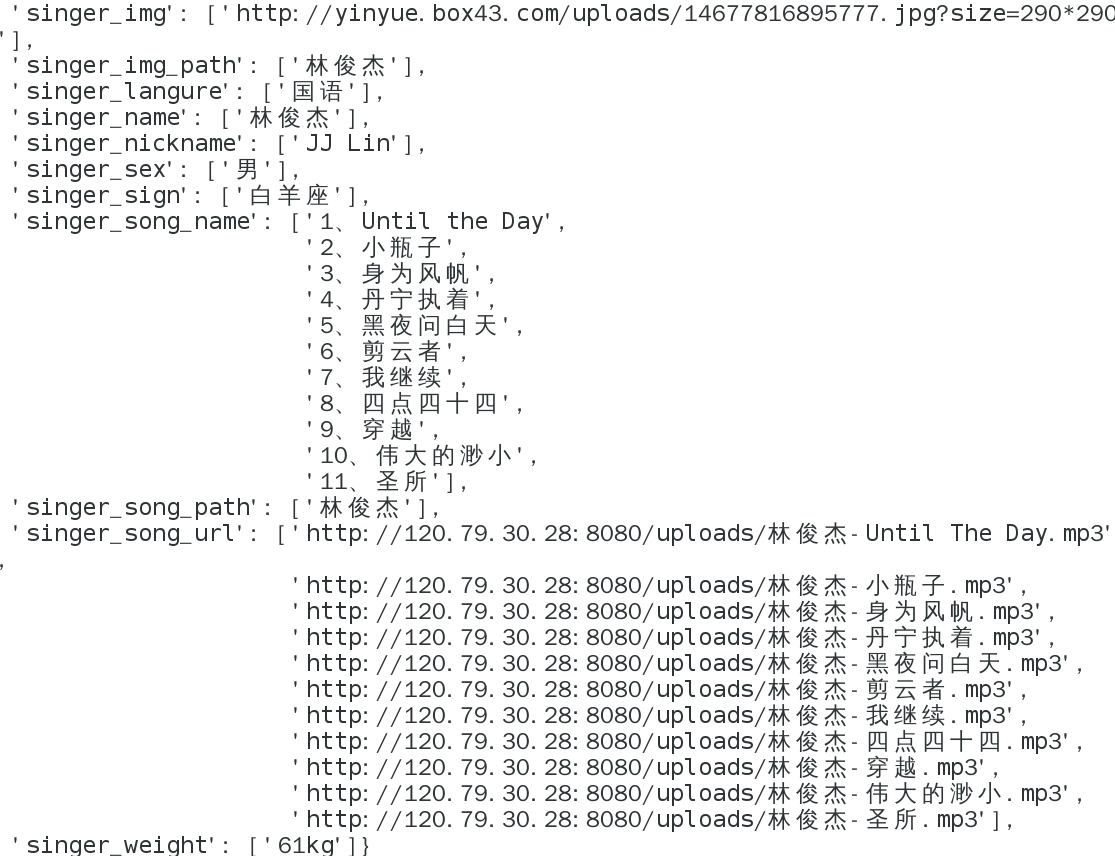
 代码如下:
代码如下:
class MyimagePipeline(ImagesPipeline):
20 ----
21 def get_media_request(self, item, spider):
22 for url_tmp in item["singer_img"]:
23 if url_tmp != '':
24 yield Request(url=url_tmp, meta={"item":item, "file_name":item["singer_img_path"]})
25 ----
26 def file_path(self, request, response=None, info=None):
27 item = request.meta["item"]
28 image_name = item["singer_name"]+".jpg"
29 dir_name = request.meta["file_name"]
30 dir_name = re.sub(r'[?\*|"<>:/]', '', name)
31 filename = u'{0}/{1}'.format(dir_name, image_name)
32 print('=='*20)
33 print(filename)
34 print('=='*20)
35 return filename
配置文件设置如下:
67 ITEM_PIPELINES = {
68 #'mp3.pipelines.Mp3Pipeline': 300,
69 #'mp3.pipelines.MyfilePipeline': 150,
70 'mp3.pipelines.SongPipeline': 100,
71 'mp3.pipelines.MyimagePipeline': 4,
72 }
73 IMAGES_STORE='/root/workspace/pcap/mp3/mp3/File/'
注意:
其中spider中已经将所有定义要提取的数据已经获取到了,其中MyfilePipeline是将提取出来的数据写在文件里边这个是没有问题的,剩下的两个SongPipeline和MyimagePipeline分别为下载歌曲和下载图片的,使用pdb在这两个类中打断点代码不会进去





