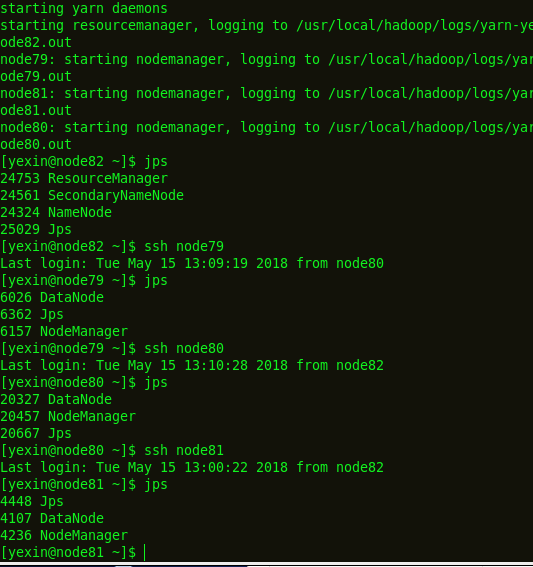
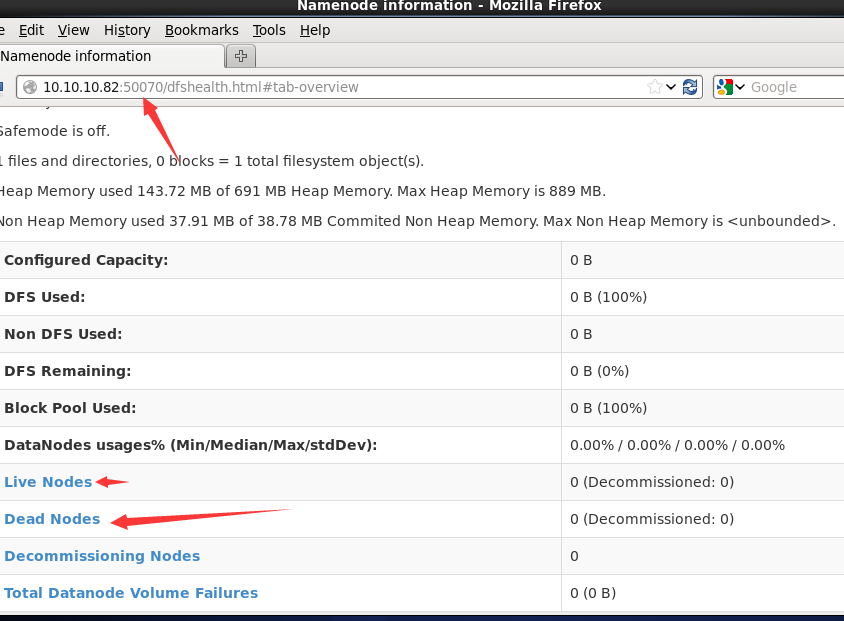
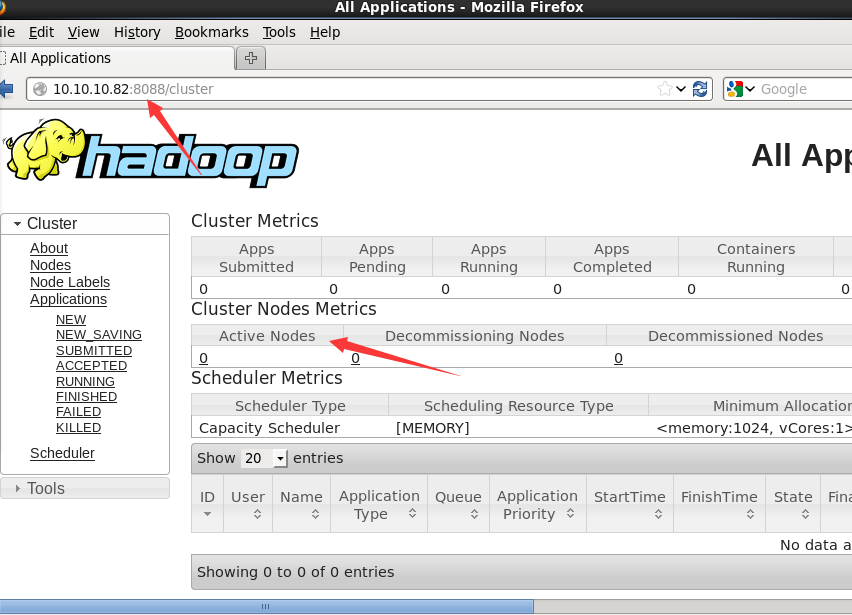
node82作为namenode节点,node81,node80,node79作为datanode,jps显示都是启动的,可以登陆网页却看不到datanode节点信息。
收起
看一下几个cluster 的日志肯定是有报错的
报告相同问题?

 分享
分享


