
python3下如何在所有子线程执行完毕后再运行主线程?
下边是我的代码,再此基础上应该如何修改?
我程序大概意思就是:
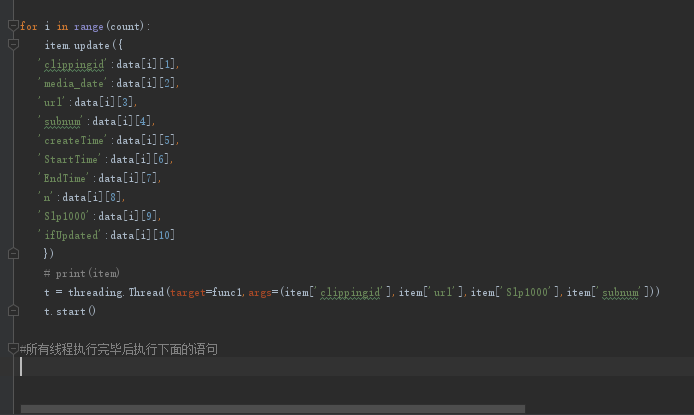
先进行for 循环,每次循环创建1个线程,然后都执行func1这个函数,每次循环传递给func1的参数都不同,
我想在所有子线程运行结束后,再执行下边的代码,请高手帮忙,如何在我代码基础上进行修改?

python3下如何在所有子线程执行完毕后再运行主线程?
下边是我的代码,再此基础上应该如何修改?
我程序大概意思就是:
先进行for 循环,每次循环创建1个线程,然后都执行func1这个函数,每次循环传递给func1的参数都不同,
我想在所有子线程运行结束后,再执行下边的代码,请高手帮忙,如何在我代码基础上进行修改?
 分享
分享 import threading
def pr(i):
print(i)
thread = []
for i in list(range(100)):
k = threading.Thread(target=pr, args=(i,))
thread.append(k)
for j in thread:
j.start()
for k in thread:
k.join()
print('已经完成了?')
你测试一下这个代码,‘已经完成了’是在打印0-99之后才显示出来的
分享


