需求:需要实现从sqlserver库中导入数据到mysql中,但实际上只导入了1条记录就结束了(实际数据600+条)。
查看了原因: 应该就是行分隔符引起了 只导入了一条就结束了 。
代码:
1、通过sqoop脚本将sqlserver导入到hdfs中:
sqoop import \
--connect "jdbc:sqlserver://192.168.1.130:1433;database=测试库" \
--username sa \
--password 123456 \
--table=t_factfoud \
--target-dir /tmp/sqoop_data/900804ebea3d4ec79a036604ed3c93a0_2014_yw/t_factfoud9 \
--fields-terminated-by '\t' --null-string '\N' --null-non-string '\N' --lines-terminated-by '\001' \
--split-by billid -m 1
2、通过sqoop脚本将hdfs数据导出到mysql中:
sqoop export \
--connect 'jdbc:mysql://192.168.1.38:3306/xiayi?useUnicode=true&characterEncoding=utf-8' \
--username root \
--password 123456 \
--table t_factfoud \
--export-dir /tmp/sqoop_data/900804ebea3d4ec79a036604ed3c93a0_2014_yw/t_factfoud9 \
-m 1 \
--fields-terminated-by '\t' \
--null-string '\N' --null-non-string '\N' \
--lines-terminated-by '\001'
现在执行结果:
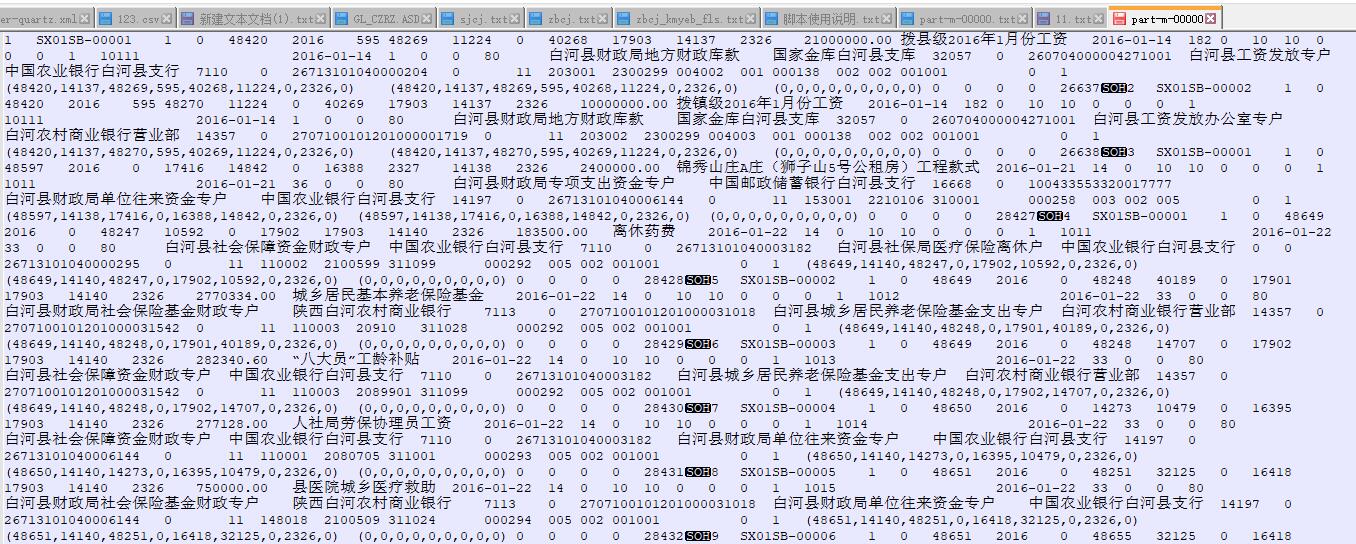
1、sqlserver库中 表 t_factfoud 中有 600 条记录,已正确到到hdfs中 。
2、从hdfs导出到mysql,只正确导入了一条,就结束了。
效果图如下: