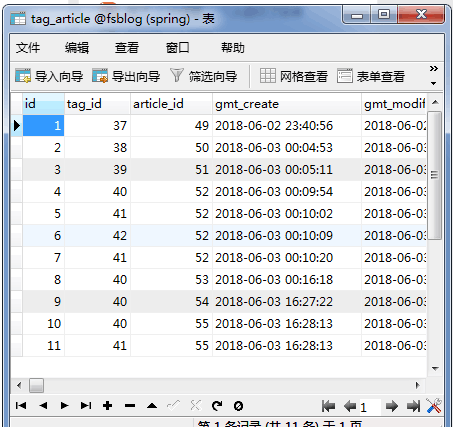
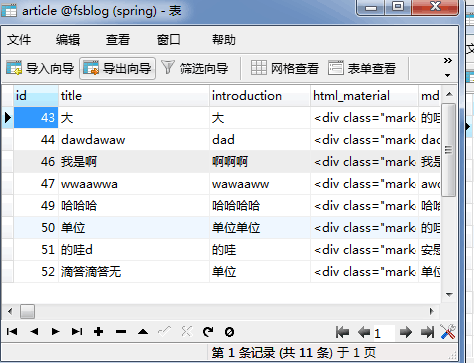
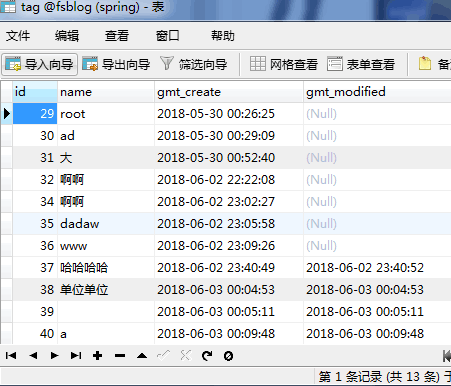
 如图,有张中间表,怎么通过article表的id查询article表中所有的值已经tag表中的name字段的值,name可能是多个,小弟刚入行没多久,多谢各位解答
如图,有张中间表,怎么通过article表的id查询article表中所有的值已经tag表中的name字段的值,name可能是多个,小弟刚入行没多久,多谢各位解答

mysql多表查询,有个中间表,如何查询
# ##
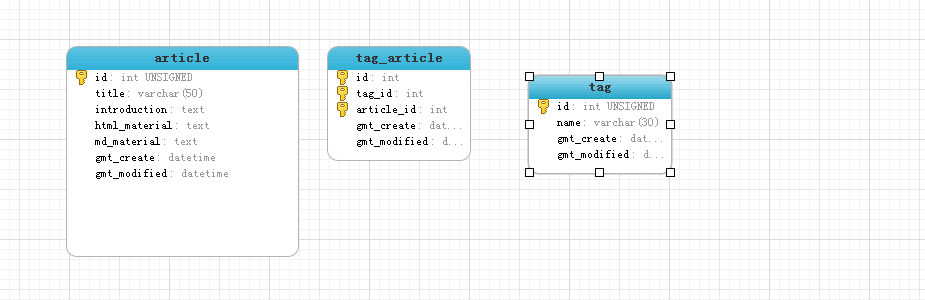 如何通过article表中的id查询article表下面的内容以及tag下面的name字段的值,一条article的数据可能有多个tag表的name
如何通过article表中的id查询article表下面的内容以及tag下面的name字段的值,一条article的数据可能有多个tag表的name
- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

7条回答 默认 最新
- weixin_41497737 2018-06-03 12:32关注
select a.title , t.name from article a
left join tag_article ta on a.id = ta.article_id
join tag t on ta.tag_id = t.id查询出来是这个样子的.
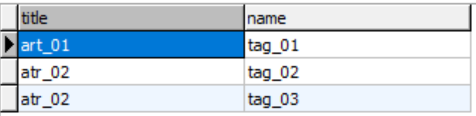
这里并没有展示article表中的所有字段,是为能更加清晰的查看查询结果.
说明一下思路 :
1.首先,是一对多的关系,那么肯定有一个非等值连接.使用左连接或者右连接,在这里,我是把article
表放在了前面,所以使用了左连接,使得article表中的值能对应多个tag中name.
2.那么,还有一个中间表,你可以这么思考,把中间表和tag的查询结果当做一个表.所以中间表和tag
直接用等值连接就可以了.ok了.
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决评论 打赏无用 1举报 分享
- 2018-11-20 10:42susu11581147324的博客 千万级别的表中获取分页数据(尤其在获取第百万页的数据时,查询时间差别明显) select * from score WHERE 1=1 AND score_status =1 limit 11014490,400000 平均80-90秒 select * from score WHERE 1=1 ...
- 2022-09-04 22:14Yuleo_的博客 在表关系的笛卡尔积中,不仅保留表关系中所有匹配的数据记录,而且还保留部分不匹配的记录。关系:一对一关系,多用于单...如示例所示,直接插入两个表进行查询,会导致一个表中的一条数据,对应另一个表中的所有数据。
- 2024-09-10 19:24解怡椿的博客 分享了MySQL中的多表查询和子查询,大量实例让你看到爽
- 2022-12-27 18:25W_chuanqi的博客 执行如下脚本,创建emp表与dept表并插入测试数据-- 创建dept表,并插入数据(name varchar(50) not null comment '部门名称') comment '部门表';VALUES (1, '研发部'),(2, '市场部'),(3, '财务部'),(4, '销售部'),(5...
- 2023-05-25 10:1925G的博客 查询首先是要进行创建时间降序排序,所以联合索引的第一个字段就使用创建时间字段,其余条件跟上即可。
- 2022-07-15 10:37爱笑的蛐蛐的博客 关联另一方的主键2)多对多实现建立第三张中间表,至少有两个主键,分别关联两方主键3)一对一实现任意一方建立外键关联另一方主键,并且设置外键为唯一的(unique)概述从多张表中查询数据笛卡尔积在多表查询中会出现...
- 2024-03-26 16:50海绵_青年的博客 多表查询是在Web开发时候比较常用的操作。一般复杂一点的项目,都需要进行多表查询。本文以自建数据表,完成多表查询的讲解学习。
- 2024-04-30 17:49赛博末影猫的博客 SQL(结构化查询语言),处理结构化数据的查询语言,结构化数据就是一张表,数据结构是关系,元组的结合MySQL是关系型数据库,存储的是关系模型数据。MySQL是一种计算机语言,,MySQL也不例外,一张表,往往就是对...
- 2020-09-09 07:541. **UNION查询**:在合并多个查询结果时,MySQL可能会创建临时表来合并结果集。 2. **TEMPTABLE算法或UNION查询中的视图**:当查询涉及到视图并且使用了UNION操作,MySQL可能需要临时表来存储中间结果。 3. **...
- 2020-10-30 05:14MySQL中的LIMIT查询是一个非常常用的分页查询功能,它可以帮助开发者从大量的数据集中提取特定范围的记录。尽管LIMIT在进行数据分页时非常便捷,但在处理大数据量时,LIMIT查询可能会遇到性能瓶颈,特别是在涉及到大...
- 没有解决我的问题, 去提问

