
现在生产上有一个rabbitmq(RabbitMQ 3.6.3, Erlang 18.1),三个节点,普通集群,集群前面有一个haproxy进行负载均衡,最近发现集群中的三个节点会随机出现宕掉的情况,影响业务。
下面是haproxy的配置
global
log 127.0.0.1 local0
log 127.0.0.1 local2 info
maxconn 4096
user haproxy
group haproxy
daemon
pidfile /var/run/haproxy.pid
defaults
log global
mode tcp
option tcplog
option dontlognull #保证HAProxy不记录上级负载均衡发送过来的用于检测状态没有数据的心跳包
retries 3 #重试次数
option redispatch
maxconn 4096 #最大连接数
#balance source #如果想让HAProxy按照客户端的IP地址进行负载均衡策略,即同一IP地址的所有请求都发送到同一服务器时需要配置此选项
balance leastconn
timeout connect 5000
timeout client 70000
timeout server 70000
listen admin_stat
#haproxy的web管理端口 8888,自行设置
bind 0.0.0.0:8888
mode http
stats refresh 30s
#haproxy web管理url,自行设置
stats uri /haproxy_stats
stats realm Haproxy\ Statistics
#haproxy web管理用户名密码,自行设置
stats auth admin:Byb1Asr9
stats hide-version
listen rabbitmq
#监听5672端口(如果haproxy安装在集群节点上时请选择非5672端口如5670),并转发给三个节点的5672端口,采用轮询策略
bind 0.0.0.0:5672
mode tcp
balance roundrobin
server rabbitmq-1 192.168.1.15:5672 check inter 2000 rise 2 fall 3
server rabbitmq-2 192.168.1.16:5672 check inter 2000 rise 2 fall 3
server rabbitmq-3 192.168.1.17:5672 check inter 2000 rise 2 fall 3
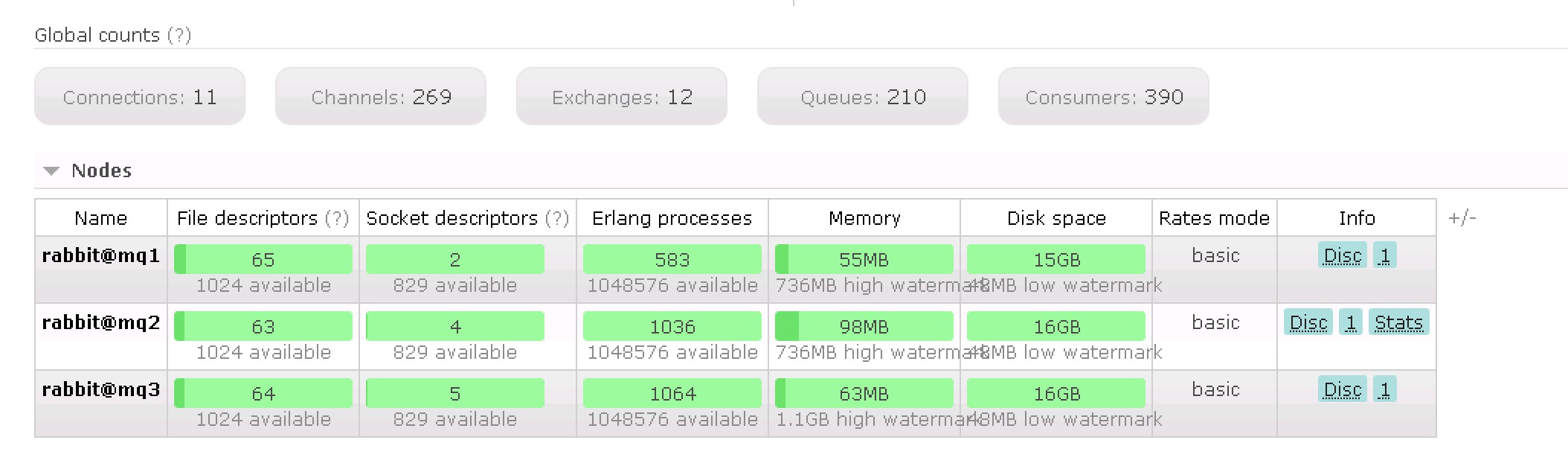
下图是rabbitmq的信息
节点宕掉的时候,在节点的mq日志(rabbitmq@mq1.log)里只能看到下面的信息,没有其他的错误信息
在系统的/var/log/message这个时间段,没有出现错误。
=INFO REPORT==== 5-Jun-2018::01:30:09 ===
accepting AMQP connection <0.227.33> (192.168.1.7:43276 -> 192.168.1.16:5672)
=INFO REPORT==== 5-Jun-2018::01:30:09 ===
accepting AMQP connection <0.224.33> (192.168.1.7:43279 -> 192.168.1.16:5672)
=INFO REPORT==== 5-Jun-2018::01:30:09 ===
accepting AMQP connection <0.294.33> (192.168.1.7:43282 -> 192.168.1.16:5672)
=WARNING REPORT==== 6-Jun-2018::12:18:07 ===
closing AMQP connection <0.227.33> (192.168.1.7:43276 -> 192.168.1.16:5672):
client unexpectedly closed TCP connection
=INFO REPORT==== 6-Jun-2018::19:14:47 ===
rabbit on node rabbit@mq1 down
=INFO REPORT==== 6-Jun-2018::19:14:47 ===
accepting AMQP connection <0.16310.70> (192.168.1.7:42508 -> 192.168.1.16:5672)
=INFO REPORT==== 6-Jun-2018::19:14:47 ===
accepting AMQP connection <0.16320.70> (192.168.1.7:42511 -> 192.168.1.16:5672)
=INFO REPORT==== 6-Jun-2018::19:14:48 ===
accepting AMQP connection <0.16390.70> (192.168.1.7:42514 -> 192.168.1.16:5672)
=INFO REPORT==== 6-Jun-2018::19:14:48 ===
Statistics event collector started.
在/var/log/secure里宕掉的时间点有如下日志,其他的信息都没有了:
Jun 6 19:14:48 mq1 su: pam_unix(su:session): session closed for user rabbitmq
想问一下,各位,有没有谁碰到类似的问题,或者能否提供一些解析问题的思路?谢谢了





