
目标爬取网站为http://www.ccgp-shaanxi.gov.cn/notice/list.do?noticetype=3&province=province
form data为: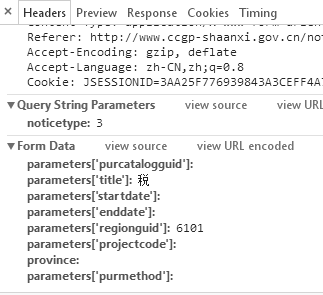
以下为我的代码:
import requests
from urllib.parse import urlencode
base_url = 'http://www.ccgp-shaanxi.gov.cn/notice/noticeaframe.do?noticetype='
noticetype = '3'
url = base_url + noticetype
headers = {
'Host': 'www.ccgp-shaanxi.gov.cn',
'Referer': 'http://www.ccgp-shaanxi.gov.cn/notice/list.do?noticetype=3&province=province',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'}
data = {
'parameters[purcatalogguid]': '',
'page.pageNum': '',
'parameters[title]': '税',
'parameters[startdate]': '',
'parameters[enddate]': '',
'parameters[regionguid]': '6101',
'parameters[projectcode]': '',
'province': '',
'parameters[purmethod]': ''
}
data = urlencode(data)
print(data)
request = requests.post(url, data=data, headers=headers)
# print(request.text)
print(request.headers)
但是获取到的信息反应、感觉formdata貌似没有起作用,因本人属于新手小白,各位大神能指点指点吗?





