
sqoop import命令在窗口直接执行时没有问题的,但是通过oozie去调用就出现这种问题
oozie调用sqoop list-databases也是可以成功的
有没有大神给分析一下是哪些地方的问题,内存不足还是什么问题
workflow.xml
<action name="sqoop-node">
<sqoop xmlns="uri:oozie:sqoop-action:0.3">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<command>import --connect jdbc:mysql://10.148.1.100:3306/test --username root --password 123456 --table person --target-dir /user/root/testSqoop/output --fields-terminated-by "," --num-mappers 1 --direct</command>
</sqoop>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Sqoop failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
oozie console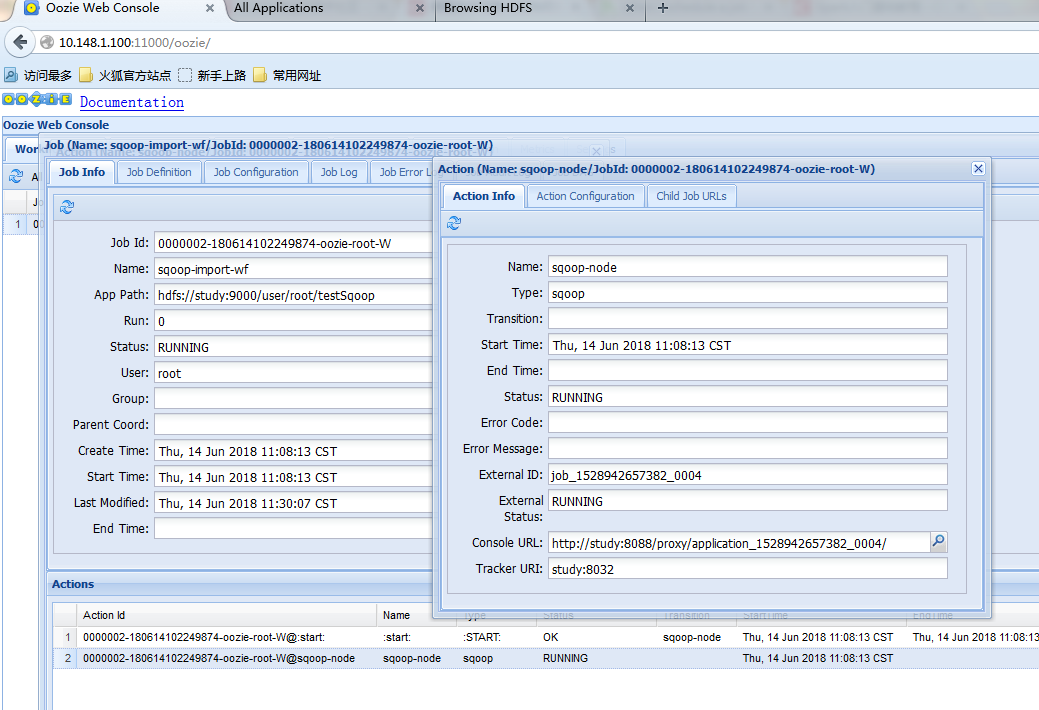
hadoop applacation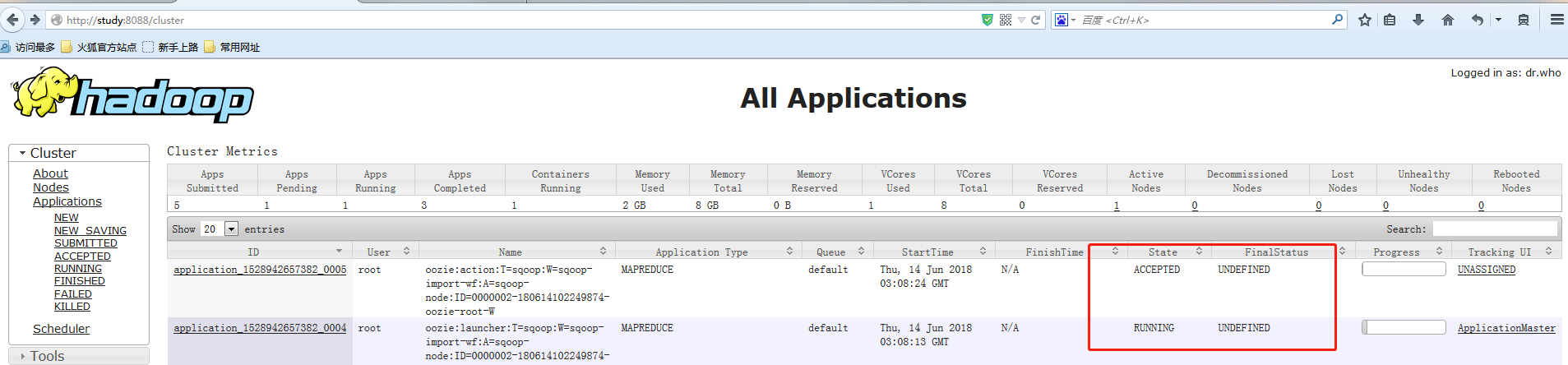

疑问为什么会起两个 MAPREDUCE任务
虚拟机内存情况
日志信息
2018-06-14 11:08:20,625 [uber-SubtaskRunner] WARN org.apache.sqoop.tool.SqoopTool - $SQOOP_CONF_DIR has not been set in the environment. Cannot check for additional configuration.
2018-06-14 11:08:20,649 [uber-SubtaskRunner] INFO org.apache.sqoop.Sqoop - Running Sqoop version: 1.4.6
2018-06-14 11:08:20,664 [uber-SubtaskRunner] WARN org.apache.sqoop.tool.BaseSqoopTool - Setting your password on the command-line is insecure. Consider using -P instead.
2018-06-14 11:08:20,676 [uber-SubtaskRunner] WARN org.apache.sqoop.ConnFactory - $SQOOP_CONF_DIR has not been set in the environment. Cannot check for additional configuration.
2018-06-14 11:08:20,779 [uber-SubtaskRunner] INFO org.apache.sqoop.manager.MySQLManager - Preparing to use a MySQL streaming resultset.
2018-06-14 11:08:20,784 [uber-SubtaskRunner] INFO org.apache.sqoop.tool.CodeGenTool - Beginning code generation
2018-06-14 11:08:21,235 [uber-SubtaskRunner] INFO org.apache.sqoop.manager.SqlManager - Executing SQL statement: SELECT t.* FROM person AS t LIMIT 1
2018-06-14 11:08:21,261 [uber-SubtaskRunner] INFO org.apache.sqoop.manager.SqlManager - Executing SQL statement: SELECT t.* FROM person AS t LIMIT 1
2018-06-14 11:08:21,266 [uber-SubtaskRunner] INFO org.apache.sqoop.orm.CompilationManager - HADOOP_MAPRED_HOME is /opt/hadoop-2.6.0
2018-06-14 11:08:23,470 [uber-SubtaskRunner] INFO org.apache.sqoop.orm.CompilationManager - Writing jar file: /tmp/sqoop-root/compile/8750ac72c9db5da23fa902b0a16d1957/person.jar
2018-06-14 11:08:23,485 [uber-SubtaskRunner] INFO org.apache.sqoop.manager.DirectMySQLManager - Beginning mysqldump fast path import
2018-06-14 11:08:23,485 [uber-SubtaskRunner] INFO org.apache.sqoop.mapreduce.ImportJobBase - Beginning import of person
2018-06-14 11:08:23,486 [uber-SubtaskRunner] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
2018-06-14 11:08:23,491 [uber-SubtaskRunner] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.jar is deprecated. Instead, use mapreduce.job.jar
2018-06-14 11:08:23,505 [uber-SubtaskRunner] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
2018-06-14 11:08:23,509 [uber-SubtaskRunner] WARN org.apache.sqoop.mapreduce.JobBase - SQOOP_HOME is unset. May not be able to find all job dependencies.
2018-06-14 11:08:23,559 [uber-SubtaskRunner] INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at study/10.148.1.100:8032
2018-06-14 11:08:23,928 [uber-SubtaskRunner] INFO org.apache.sqoop.mapreduce.db.DBInputFormat - Using read commited transaction isolation
2018-06-14 11:08:23,996 [uber-SubtaskRunner] INFO org.apache.hadoop.mapreduce.JobSubmitter - number of splits:1
2018-06-14 11:08:24,051 [uber-SubtaskRunner] INFO org.apache.hadoop.mapreduce.JobSubmitter - Submitting tokens for job: job_1528942657382_0005
2018-06-14 11:08:24,051 [uber-SubtaskRunner] INFO org.apache.hadoop.mapreduce.JobSubmitter - Kind: YARN_AM_RM_TOKEN, Service: , Ident: (appAttemptId { application_id { id: 4 cluster_timestamp: 1528942657382 } attemptId: 1 } keyId: 589196118)
2018-06-14 11:08:24,053 [uber-SubtaskRunner] INFO org.apache.hadoop.mapreduce.JobSubmitter - Kind: RM_DELEGATION_TOKEN, Service: 10.148.1.100:8032, Ident: (owner=root, renewer=oozie mr token, realUser=root, issueDate=1528945693299, maxDate=1529550493299, sequenceNumber=3, masterKeyId=2)
2018-06-14 11:08:24,211 [uber-SubtaskRunner] WARN org.apache.hadoop.mapreduce.v2.util.MRApps - cache file (mapreduce.job.cache.files) hdfs://study:9000/user/root/testSqoop/lib/sqoop-1.4.6-hadoop200.jar conflicts with cache file (mapreduce.job.cache.files) hdfs://study:9000/tmp/hadoop-yarn/staging/root/.staging/job_1528942657382_0005/libjars/sqoop-1.4.6-hadoop200.jar This will be an error in Hadoop 2.0
2018-06-14 11:08:24,213 [uber-SubtaskRunner] WARN org.apache.hadoop.mapreduce.v2.util.MRApps - cache file (mapreduce.job.cache.files) hdfs://study:9000/user/root/testSqoop/lib/mysql-connector-java.jar conflicts with cache file (mapreduce.job.cache.files) hdfs://study:9000/tmp/hadoop-yarn/staging/root/.staging/job_1528942657382_0005/libjars/mysql-connector-java.jar This will be an error in Hadoop 2.0
2018-06-14 11:08:24,265 [uber-SubtaskRunner] INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1528942657382_0005
2018-06-14 11:08:24,301 [uber-SubtaskRunner] INFO org.apache.hadoop.mapreduce.Job - The url to track the job: http://study:8088/proxy/application_1528942657382_0005/
2018-06-14 11:08:24,301 [uber-SubtaskRunner] INFO org.apache.hadoop.mapreduce.Job - The url to track the job: http://study:8088/proxy/application_1528942657382_0005/
2018-06-14 11:08:24,302 [uber-SubtaskRunner] INFO org.apache.hadoop.mapreduce.Job - Running job: job_1528942657382_0005
2018-06-14 11:08:24,302 [uber-SubtaskRunner] INFO org.apache.hadoop.mapreduce.Job - Running job: job_1528942657382_0005
2018-06-14 11:08:25,976 [communication thread] INFO org.apache.hadoop.mapred.TaskAttemptListenerImpl - Progress of TaskAttempt attempt_1528942657382_0004_m_000000_0 is : 1.0
2018-06-14 11:08:25,976 [communication thread] INFO org.apache.hadoop.mapred.TaskAttemptListenerImpl - Progress of TaskAttempt attempt_1528942657382_0004_m_000000_0 is : 1.0
Heart beat
2018-06-14 11:08:56,045 [communication thread] INFO org.apache.hadoop.mapred.TaskAttemptListenerImpl - Progress of TaskAttempt attempt_1528942657382_0004_m_000000_0 is : 1.0
2018-06-14 11:08:56,045 [communication thread] INFO org.apache.hadoop.mapred.TaskAttemptListenerImpl - Progress of TaskAttempt attempt_1528942657382_0004_m_000000_0 is : 1.0
Heart beat
2018-06-14 11:09:26,082 [communication thread] INFO org.apache.hadoop.mapred.TaskAttemptListenerImpl - Progress of TaskAttempt attempt_1528942657382_0004_m_000000_0 is : 1.0
2018-06-14 11:09:26,082 [communication thread] INFO org.apache.hadoop.mapred.TaskAttemptListenerImpl - Progress of TaskAttempt attempt_1528942657382_0004_m_000000_0 is : 1.0
Heart beat




