
这是源码
# -*- coding: utf-8 -*-
# @Time : 2018/6/22 22:44
# @Author : yyc
# @File : 爬虫2.py
# @Software : PyCharm
#======================================================
import urllib.request
import requests
import time
import random
from bs4 import BeautifulSoup
i = 0
idList = ['80749562','80765157','80753463','80753023','80752222','80751582','80751341','80748977','80781967']
url = 'https://blog.csdn.net/weixin_42246860/article/details/'
randomTimes = random.randint(1.0,3.0)
def getHTML(url):
global i
headers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
i += 1
try:
for j in range(len(idList)):
req = requests.Request(url + idList[j], headers=headers)
soup = BeautifulSoup(req.text,"html.parser")
title_list = soup.find_all("h1",class_="title-article").a.text.strip()
title = title_list[i].a.text.strip()
urllib.request.urlopen(url + idList[j]).read().decode('utf-8')
print("第 {} 次访问: ".format(i) + url + idList[j] + " 标题: %s" % title)
time.sleep(randomTimes)
print("\n******************** 第 {} 轮访问结束 ********************\n".format(i))
except:
print("错误,继续程序")
pass
def body():
while True:
getHTML(url)
body()
这是出错的部分
def body():
while True:
getHTML(url)
可是我明明缩进了啊,下面是Notepad++显示出来的缩进符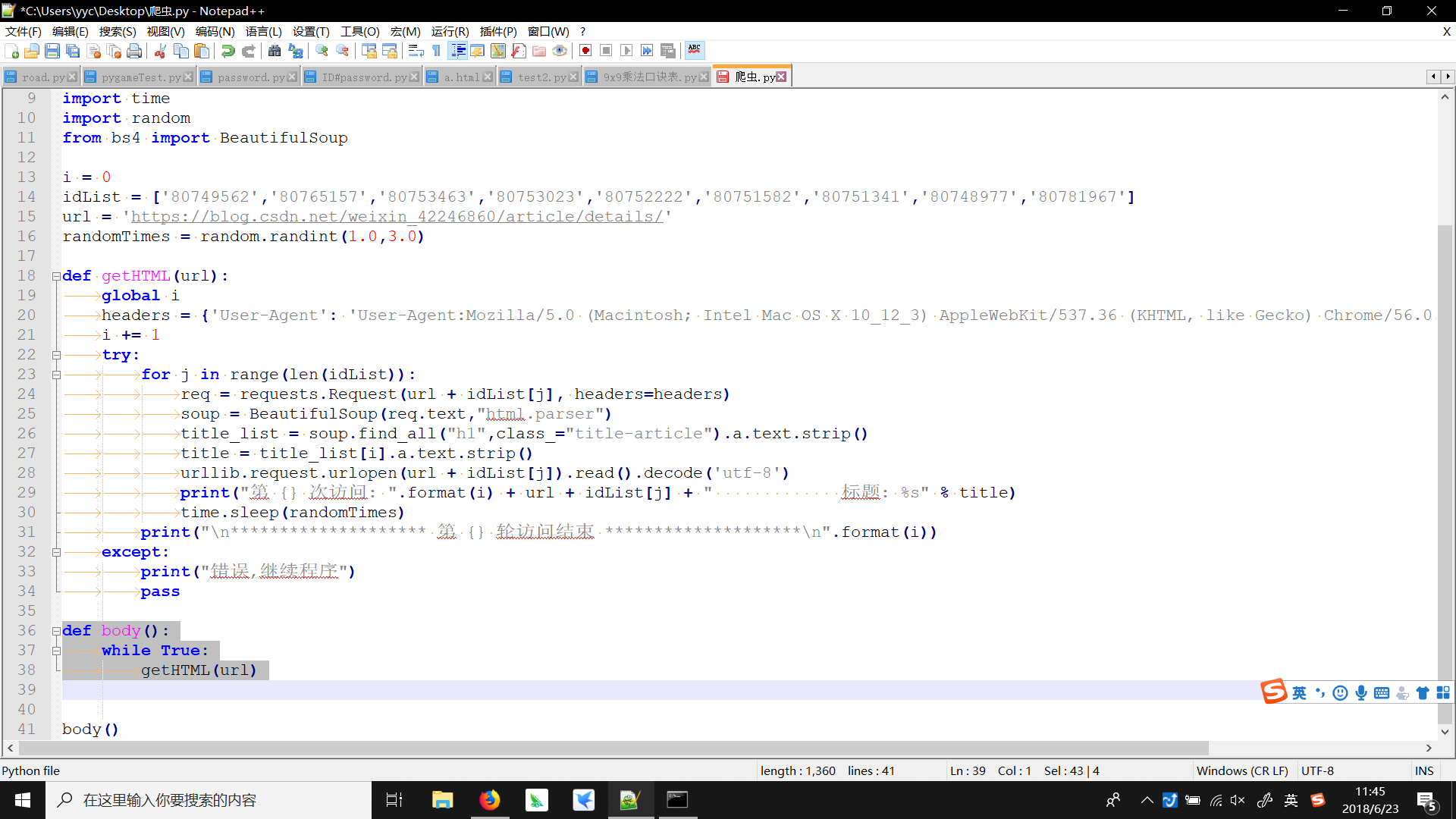
下面是详细错误
File "爬虫.py", line 33
def body():
^
IndentationError: unexpected unindent






