
最近在用python做网页模拟登陆的时候遇到一些问题。
1.cookies方面的:
当访问某个网页的子页时候往往需要发送一些cookies,这些cookies大多数能在response headers里面找到(set cookies),但是有一些属性是“脚本可访问”的却没有在在headers里面找到(即使已经清空了缓存的该网站的所有cookies),想知道这些cookies是怎么来的。JS脚本里面生成的吗?在python里面应该要怎么样得到这些cookies?
2.关于用post发送payload的问题:
在开发者工具里面发现网页发送的payload是分层次的而不是并列出现(见下图),这种情况在python里面写的时候要用什么格式写?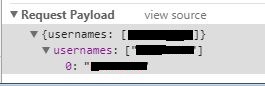
3.Query String Parameters是什么?
刚开始学习爬虫不久,对网页结构了解不是很深,觉得先前使用开发者工具分析网站的方法不是很正确,希望大神指点迷津。




