如题。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。

python sklearn的zsys模块怎么导入,验证过的请回答。。。

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新
- suchvaliant 2018-06-27 09:09关注
sklearn API参考手册都找不到zsys模块,你是要都入sys模块吗
from sklearn import sys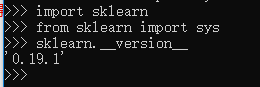 本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2022-05-10 13:30标题中的“股票数据(不包括当天) -python代码”表明这是一个使用Python编程语言获取和处理股票历史数据的项目。这个项目可能包含一个或多个Python脚本,用于从网络上抓取股票的历史交易数据,并且不包含当日最新的...
- 2021-03-11 17:43ZSys 适用于zfs系统的ZSys守护程序和客户端 ZSys是针对增强ZOL体验的Zfs SYStem工具。 它允许在同一台计算机上并行运行多个ZFS系统,获取自动快照,管理将用户数据与系统数据和持久性数据分开的复杂zfs数据集布局...
- 2021-03-17 20:43z.354的博客 一个模块可以使用另外一个模块中所有的全局变量,但是使用前需要先导入模块 导入模块的语法: import 模块名 - 导入指定模块,导入后通过 ‘ 模块名.x ’ 去使用模块中所有的全局变量 from 模块名 import 变量1,...
- 2020-08-10 23:05Gruce_L、จุ๊บ的博客 python项目接口测试: 大概流程:requests测试 - -> unittest单元测试 - -> 测试包装 代码样式: class unitTest(unittest.TestCase): #setUpClass():必须使用@classmethod 装饰器, 所有case运行之前只...
- 2024-04-12 10:122. 设置工作环境:配置好GOPATH环境变量,例如设置为`$HOME/go`,或者在Go 1.11及更高版本中,可以使用`GO111MODULE=on`来启用模块支持。 3. 获取Zabbix Agent 2源码:将Zabbix Agent 2的源代码克隆到`$GOPATH/src`...
- 2020-10-02 06:23CyrusZhou的博客 Zsys 会在安装软件时自动创建快照 下面是手动创建快照命令 sudo zsysctl save -s pulito-2020-10-01 快照使用 1、重新启动按住Esc进入Grub界面,如果直接进入了Grub 命令行,可以用normal 命令返回
- 2021-03-18 00:05Go中国的博客 近些年来,各种类型的产品得到充足的发展,交互性和...哪种优化方案能有效应对,需要反复对比测试数据,有时候还需要考虑 到代码结构上的实现,文中内容略浅显,表述不当的地方请指正。本文测试代码在这里:fastudp
- 2021-05-15 15:18weixin_39607450的博客 借助Canonical的Zsys计划,Ubuntu 20.04的ZFS改进的一部分是能够自动对APT操作进行快照,以便能够在包管理变更之后进行必要的系统回滚/恢复。我们现在已经开始尝试Ubuntu 20.04的ZFS/Zsys更改,并且到目前为止运行...
- 2023-11-13 22:35奕忆伊的博客 (或者直接在输入框中搜索模块名称,更为便捷) (2)方法二:对模块鼠标右键,选择向模型添加模块 然后按如上方法依次添加例子中所需模块: Integrator(积分模块),XY Graph,Gain(增益),Scope(示波器) 2....
- 2021-02-19 18:04Moqui-zsys
- 2025-01-16 21:38百成Java的博客 ✌️ 博主主页:百成Java 往期系列:Spring Boot、SSM、JavaWeb、python、小程序 获取源码联系方式请查看文末 前言 时代在飞速进步,每个行业都在努力发展现在先进技术,通过这些先进的技术来提高自己的水平和优势,...
- 2026-01-07 22:01m***5672的博客 设置 Nginx 开机自启: sudo systemctl enable nginx 验证 Nginx 服务 你可以使用以下命令来验证 Nginx 服务的状态: sudo systemctl status nginx 如果一切正常,你应该会看到 Nginx 服务正在运行。 总结 通过上述...
- 2026-03-21 18:53神经网络15044的博客 通过MATLAB/Simulink扫频仿真验证了模型的准确性,结果表明DR换相过程与MMC控制动态在低频段存在显著耦合,影响系统稳定性。该研究为混合直流输电系统的稳定运行提供了理论依据。 关键词:高压直流输电;二极管整流...
- 2025-12-04 04:48乌想炳Todd的博客 通过zactor,开发者可以轻松实现服务的模块化和解耦。 快速入门:CZMQ开发环境搭建 编译安装步骤 克隆仓库: git clone https://gitcode.com/gh_mirrors/cz/czmq 进入项目目录并编译: cd czmq ./autogen.sh ./...
- 2026-03-23 21:22祝大家百事可乐的博客 6 储能EMS(SCADA)核心功能与高级应用 6.1 EMS基础SCADA功能 功能模块 核心能力 数据采集 全设备模拟量、开关量、SOE采集 告警管理 分级告警、语音提示、事件追忆 数据统计 充放电电量、运行时长、站用电率统计 报表...
- 2025-11-22 01:44apple5的博客 实战案例:智能家居设备优化 最近在优化某款智能中控时,通过开机Trace发现了这些问题: zygote预加载耗时过长(8.2秒) 原因:过度预装厂商应用 解决:修改ro.zsys.preload属性 SurfaceFlinger启动阻塞(3.5秒) ...
- 2026-03-07 09:30flyair_China的博客 其中yi为第i个观测值(如CD, 深度, 角度),p为待校准参数,R(p)为正则化项防止过拟合。 2. 敏感性分析:计算输出yj对输入参数pi的敏感性系数 Sij=(∂yj/∂pi)⋅(pi/yj)。 3. 不确定性传播:若...
- 2025-08-12 09:54flyair_China的博客 检查ZVS:计算最小负载下的励磁电流Im,验证是否满足ZVS条件。 5. 损耗计算:计算导通损耗、磁芯损耗,估计效率η。 6. 迭代优化:调整Lr, Lm等参数,优化效率、ZVS范围和尺寸。 7. 控制设计:设计频率控制器...
- 2025-12-04 04:54伏崴帅的博客 无论你是构建实时通信系统还是高并发数据处理平台,这些经过实践验证的方法都能为你的项目带来明显的性能提升。 ## 1. 合理设置套接字高水位标记(HWM) 高水位标记(HWM)是控制消息队列大小的关键参数,直接影响
- 2025-07-30 05:33zzz56的博客 - &ZSYS :系统安装程序创建的符号,为 “MV” 加上 &SYSCLONE 的第一位(系统编号),例如 MV11 使 &ZSYS 为 MV1,MV21 使 &ZSYS 为 MV2。 mermaid 流程图展示符号替换流程: graph TD; A[IPL命令] --> B[LOAD成员...
- 没有解决我的问题, 去提问

