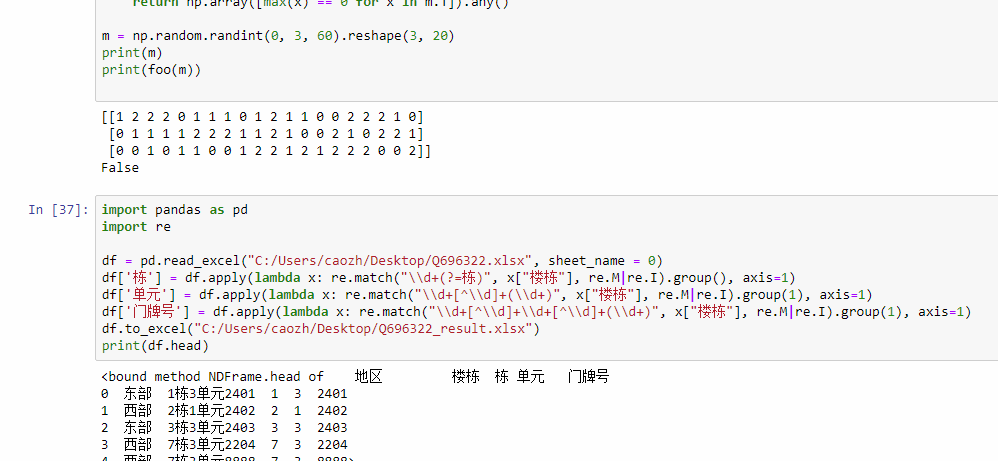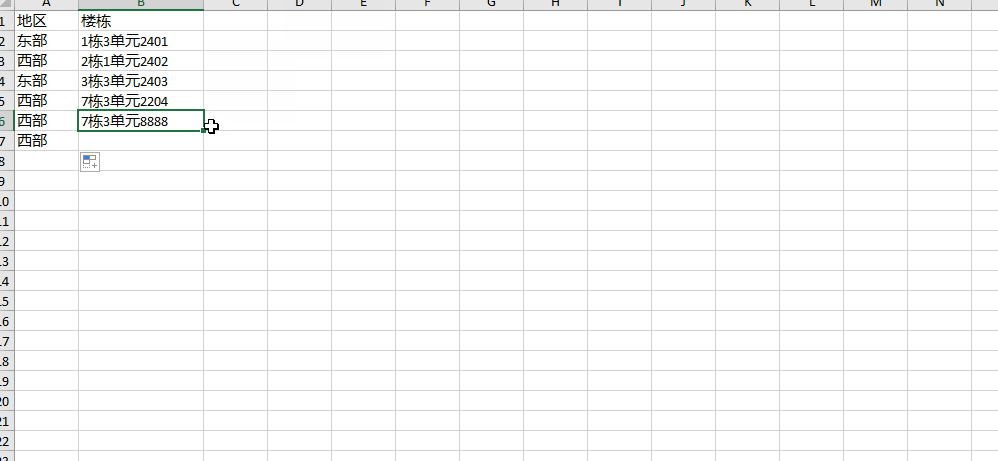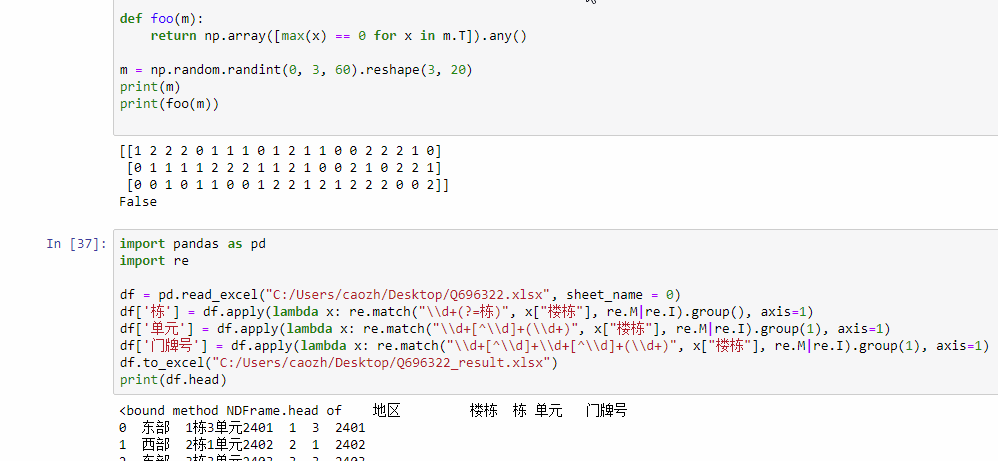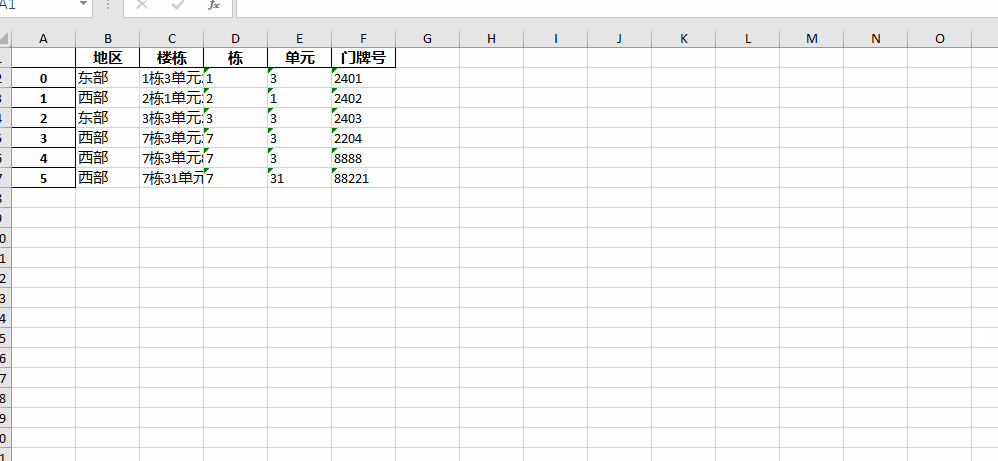
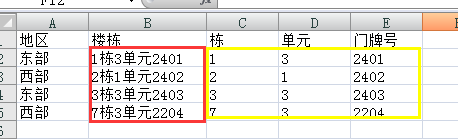
如图片,所示,如何提取楼栋里边的数字,到excel新列里边,分别提取到栋,单元,楼层三列里边,同时三列是通过python建立,不是手动建立的,有点复杂,求大神赐教。
收起
当前问题酬金
¥ 0 (可追加 ¥500)
支付方式
扫码支付
支付金额 15 元
提供问题酬金的用户不参与问题酬金结算和分配
支付即为同意 《付费问题酬金结算规则》
报告相同问题?

 分享
分享