

 我想知道谁看懂了那个递推分析的过程,尤其是那个递推式。。。能给我讲解一下吗
我想知道谁看懂了那个递推分析的过程,尤其是那个递推式。。。能给我讲解一下吗

算法:考察二分算法的平均成功查找长度1.5logn是如何计算出来的,请看图

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

4条回答 默认 最新
 洋Key 2019-03-28 21:16关注
洋Key 2019-03-28 21:16关注你说的是C(k)那个递归式吗?如果是的话请看下面的一张图片
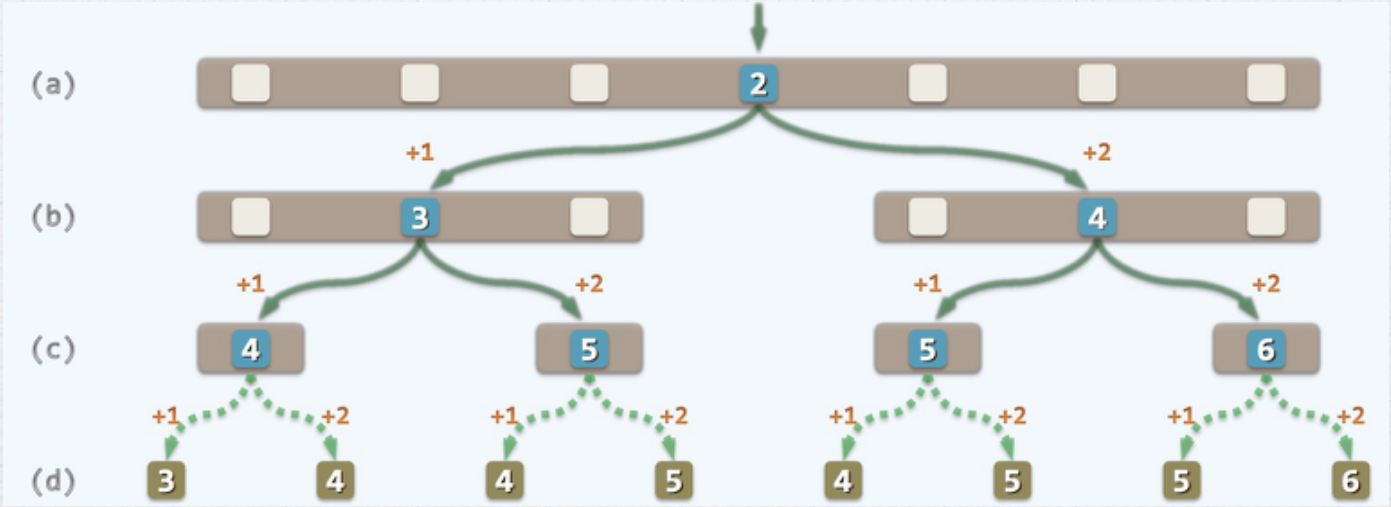
我们将(a)那一层想象成第k层,下面的(b)看作是k-1层。我们把第k层删掉,那么第k-1层就变成了顶层。
k-1层有两个分支,一左一右。你应该不难看出,顶层的查找长度(也就是一次查找成功的查找长度)必然是2。
那么对于左面的k-1层来说它的顶层是3,右面的顶层是4。稍加观察你会发现左面的k-1层的所有元素的查找长度都会相对于以k-1层为顶层时的查找长度多1。同样右面的k-1层的所有元素查找长度会相对于以k-1层为顶层时的查找长度多2。所以C(k)中需要把这些长度补上,然后在加上第k层的查找长度2即为C(k).评论 打赏解决 4无用举报 分享
- 2023-11-19 07:00软件架构师何志丹的博客 包括:二分查找的原理,证明,及样例。 分四类:自己写二分算法 有序映射 对有序向量二分查找 有序集合
- 2022-02-28 16:19Pumpkin-_-的博客 如果数组是排序的(通常按照递增的顺序排序),那么可以采用二分查找进行优化。可以取出位于数组中间的数字并和目标数字比较 如果中间数字正好等于目标数字,那么就找到了目标数字。如果中间数字大于目标数字,那么...
- 2022-05-18 16:02齐天大荒的博客 图文并茂带你入门二分查找算法 原理 二分查找(Binary Search)算法,也叫折半查找算法。二分查找的思想非常简单,有点类似分治的思想。二分查找针对的是一个有序的数据集合,每次都通过跟区间的中间元素对比,将待...
- 2021-08-13 21:53给个选择的博客 期末复习和备考408均可使用第一章:绪论(不在考研大纲但很重要)第二章:线性表第三章:栈和队列第四章:串第五章:树与二叉树第六章:图第七章:查找 第一章:绪论(不在考研大纲但很重要) 数据结构三要素:逻辑...
- 2024-04-26 20:27HollY不清醒的博客 此文章为介绍基于二分思想的查找算法实现及比较实验。
- 2024-11-13 16:12禁止默的博客 这个算法的前提是我们数据是有序排列的,这里的有序并不只是单纯的有序,有时候根据数据的排列我们可以将数据划分为两个区间,可以简称为二段性,(两段区间是有序的)且根据问题选择合适的二分思路,二分算法有基础...
- 2021-01-06 22:58程序员bigsai的博客 数据结构与算法是程序员内功体现的重要标准之一,且数据结构也应用在各个方面,业界更有程序=数据结构+算法这个等式存在。各个中间件开发者,架构师他们都在努力的优化中间件、项目结构以及算法提高运行效率和降低...
- 2021-08-08 17:08程序员springmeng的博客 最近有小伙伴面试,对数据结构和算法比较头疼,我整理了一波资料,帮助大家快速掌握数据结构和算法的面试,感觉有用的下伙伴,点赞支持哦! 不叨叨,直接上干货。 目录 Q1:数据结构和算法的知识点整理: Q2:...
- 2021-09-18 16:00linovce的博客 查询算法是非常重要的算法之一,即便不从事算法相关岗位,在CRUD的开发岗中,查询也是常见的业务操作。通常我们是从头到尾查询一个顺序表(数组、链表等)得到我们的结果,这种方式的时间复杂度为O(n),但针对一些特殊...
- 2022-07-19 19:15西皮呦的博客 假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,...
- 2025-01-01 11:27澪贰的博客 本篇是优选算法之二分查找算法,该算法是一种高效的在有序数组中查找特定元素的搜索算法
- 2024-06-14 17:49寂空_的博客 二分查找应该算是是很多人入门的第一个算法吧,无论是ACM还是蓝桥杯都是必学的算法,很多人都觉得其非常简单,但它真的那么简单吗?Knuth 大佬(发明 KMP 算法的那位)曾说过:(思路很简单,细节是魔鬼)本文将为大家...
- 2022-01-21 14:37睿科知识云的博客 二分查找又称折半查找、二分搜索、折半搜索等,是在分治算法基础上设计出来的查找算法,对应的时间复杂度为O(logn)。 二分查找算法仅适用于有序序列,它只能用在升序序列或者降序序列中查找目标元素。 二分查找算法...
- 2022-05-04 20:48Game_小志的博客 快速幂——求幂运算 O(logN)
- 2023-07-17 16:03GreyFable的博客 数据结构与算法之美总结(数组、链表、栈、队列、递归、排序及二分)
- 2021-03-11 08:33UniqueUnit的博客 目录查找【知识框架】查找概论一、查找的基本概念顺序表查找有序表查找一、折半查找二、插值查找 查找 【知识框架】 查找概论 一、查找的基本概念 查找(Searching):就是根据给定的某个值,在查找表中确定一个其...
- 2022-07-10 17:28timerring的博客 并且实现地点的查询,增加,删除以及更新操作,并且可视化整张地图,基于Dijkstra算法实现最短路径的查找与规划,完成地点无向图的构建,采用邻接矩阵的存储方式并实现以下功能: 1、输出所有地点及其介绍 2、查询...
- 2023-06-25 18:31宗浩多捞的博客 在编程中,递归是非常常见的一种算法,由于代码简洁而应用广泛,但递归相比顺序执行或循环程序,时间复杂度难以计算,而master公式就是用于计算递归程序的时间复杂度。这个步骤时,只有一个元素了 L==R,看代码 该...
- 2020-05-11 20:38XJTU_JP的博客 数据结构与算法:二路归并排序/合并排序概述:图解: 概述: List item 图解: 假设我们有这样一组数据 A[9] = {4,3,6,7,9,1,2},他在内存中这样排序
- 2023-03-24 16:54LinAlpaca的博客 二分查找算法的详细讲解,如果你还不懂二分,看这篇就对了✨✨
- 没有解决我的问题, 去提问
