有一个表如下: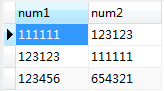
想要的查询结果为: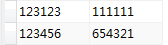
即根据num1和num2这两个字段进行去重,不论它们的先后顺序。比如:num1=111111,num2=123123和num1=123123,num2=111111就是重复的,去重并保留一条记录。

MySQL根据两列进行去重

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

7条回答 默认 最新
 路漫漫兮其修远兮 2018-09-13 09:42关注
路漫漫兮其修远兮 2018-09-13 09:42关注这个是ID是自增序列的做法,有点复杂,如果你的ID是UUID的话这个方式还是有问题。
SELECT * FROM tt WHERE ID NOT IN ( SELECT * FROM ( SELECT t1.ID FROM tt AS t1 INNER JOIN tt AS t2 ON t1.a = t2.b AND t1.b = t2.a AND t1.ID != t2.ID GROUP BY t1.id + t2.id ) AS t )如果按照这个写法中途遇到了group by的错误执行下面语句
-- 修改mysql中的group by 要求查询字段全部在group by后的设置
set global sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'; set session sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';如果不是自增ID的话,我在想想还有什么别的写法
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2023-02-01 13:33君轶79的博客 MySQL重复数据处理
- 2020-12-15 19:24假设我们有一个`aa_list`表,其中包含两列`id`和`list_name`,如下所示: | id | list_name | |----|-----------| | 1 | A | | 1 | B | | 2 | C | | 2 | D | | 3 | E | 如果我们想要将相同`id`下的`list_name`合并...
- 2024-07-19 22:13侧耳倾听童话的博客 密码:123456 python Python-3.9.0.tgz 3.9.0版本的Python MySQL Connector mysql-connector-java-5.1.32-bin.jar Spark 连接MySQL的驱动 IntelliJ IDEA Ultimate 2020.3 编程工具IDEA 大数据集群运行时,Spark...
- 2024-09-23 20:47双木的木的博客 为提高平台GMV和实现精细化运营,本项目首先使用MySQL(实际上是用Navicat Premium连接了MySQL,方便数据导入)对来自某电商的数据集进行数据预处理,然后通过多维度拆解,从用户和商品两个大的角度分别进行分析,...
- 2018-07-24 20:03砖业洋__的博客 全网最详细MySQL教程,2023持续更新中
- 2024-08-08 23:12侧耳倾听童话的博客 节点/组件/安装包版本备注名称节点master数据节点...HDFS系统访问端口为:hdfs://192.168.126.10:9000Hivehive-3.1.2数据仓库PySparkSpark集群的master节点的地址和端口为:spark://192.168.126.10:7077MySQL5.7.18。
- 2025-01-05 16:16Nightselfhurt的博客 官网下载并安装,解压打开conf的配置文件,根据项目填写相关名称,用户accesskey信息等,最后cmd进入bin目录 ,odpscmd.bat即可运行,quit退出,-f执行文件内的命令,-e参数可以执行sql语句,use 项目 可以跳转到另...
- 2025-07-23 21:23浅慕Antonio的博客 MySQL索引与约束概述 MySQL索引是一种特殊的数据结构,用于加速数据查询,主要包括以下几种类型: 主键索引:唯一标识记录,具有唯一性和非空特性 普通索引:基础索引类型,无约束性 唯一索引:保证数据唯一性 组合...
- 2026-03-12 17:46问剑白玉京丶的博客 2026年广东省职业院校技能大赛中职组&...项目二涉及数据获取与清洗,要求使用pandas处理气象数据,包括数据清洗、格式转换和去重等操作,并进行气温等级分类标注。参赛者需将各任务执行结果按要求截图并提交至文档中。
- 2023-02-24 15:37sober30的博客 数据类型类型类型举例整数浮点定点数DECIMAL位类型BIG日期时间类型文本字符串枚举...集合类型:MULTIPOINT、MULTILINESTRING、MULTPOLYGON、GEOMETRYCOLLECTION数据类型属性mysql关键字含义NULL数据列可包含NULL值。
- 没有解决我的问题, 去提问

