import requests
url = "https://movie.douban.com/top250"
headers = {'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
res = requests.get(url,headers=headers)
print (res)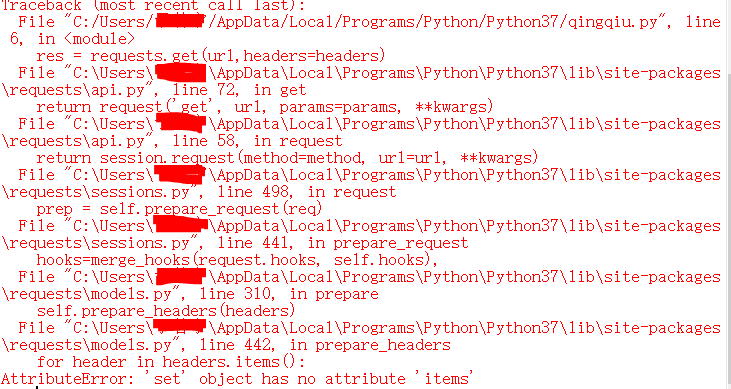

import requests
url = "https://movie.douban.com/top250"
headers = {'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
res = requests.get(url,headers=headers)
print (res)
 分享
分享





