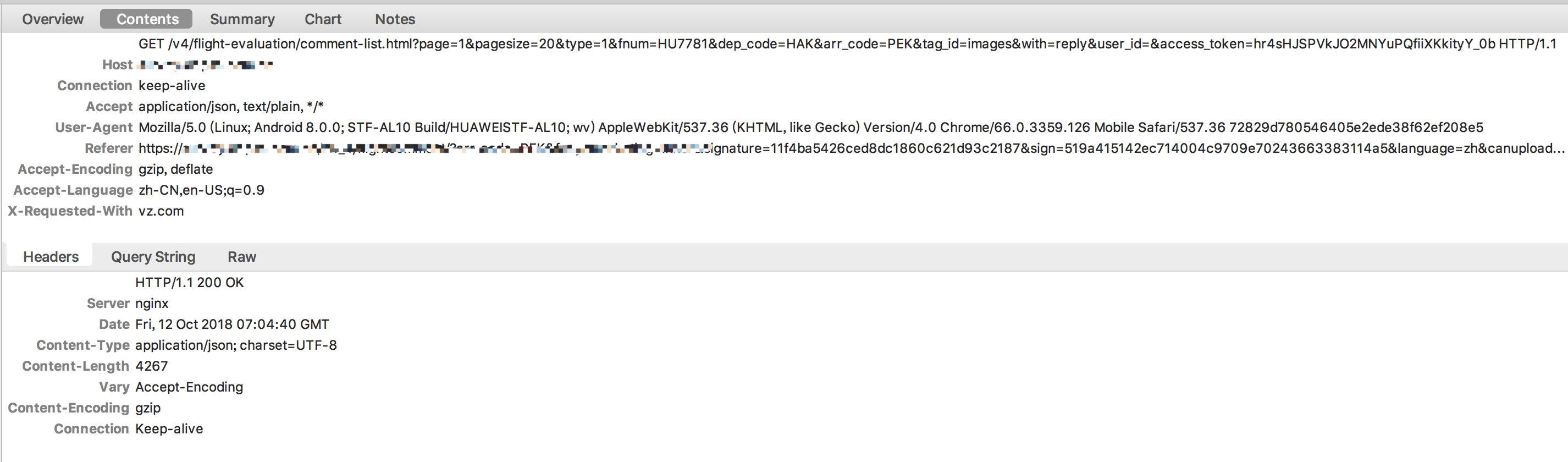
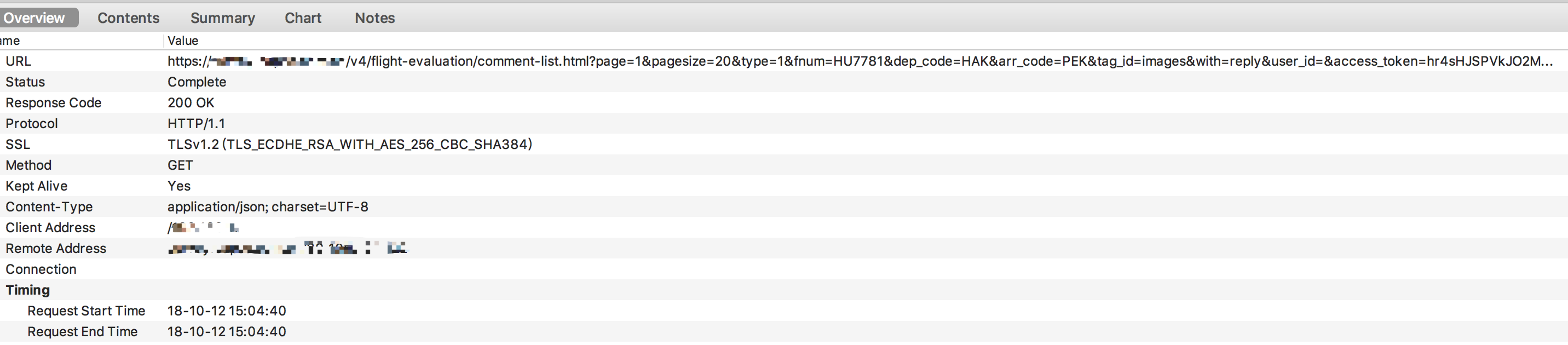
python爬虫新手,想爬取一个app评论图,用charles抓包获得url,
在浏览器上能打开是一个xml文件,但是用request.get(url,header)请求开始报错405,将https改为http后报错404
实在找不出问题是什么限制访问了,望大神解答~~~
url= "https://*********************/comment-list.html?page=1&pagesize=20&type=1&fnum=HU7781&dep_code=HAK&arr_code=PEK&tag_id=images&with=reply&user_id=&access_token=jwZ9PW62rrHUWG3ZSJehX-c9PzuSEya0"(真实网址host已用*代替)**
charles报文如下