搭建了hadoop-ha配置,node01中namenode可用浏览器访问,如下图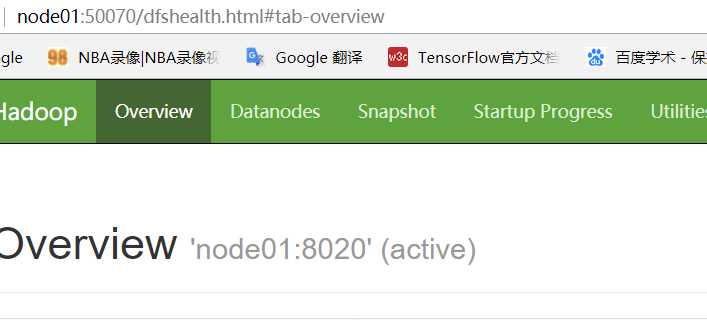
而node02用浏览器访问时,输入节点名称无法访问,输入ip地址可以访问,如下图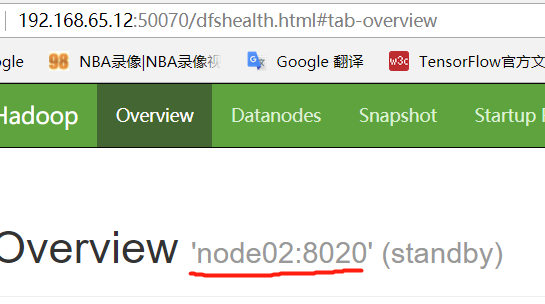
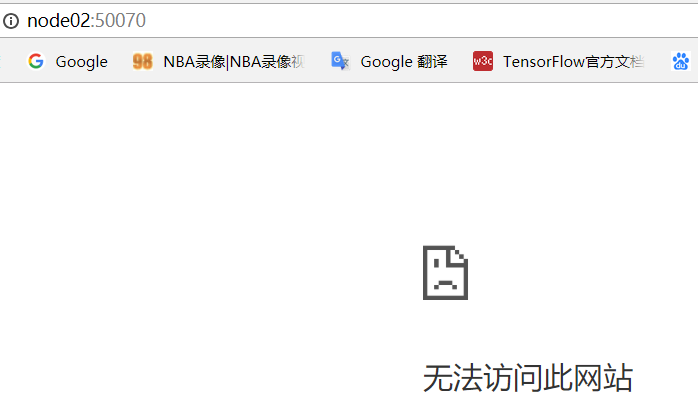
防火墙已关闭,在node01中ping node02也可ping通
请问这是为什么,如何才能成功使用node02:50070访问?

hadoop集群的namenode节点无法从浏览器访问?

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新
 michaelbournelisihao 2018-10-16 15:15关注
michaelbournelisihao 2018-10-16 15:15关注看样子是没有添加主机名和IP的映射关系。解决方法如下:
在node2节点中,在/etc/hosts文件中,添加:“192.168.65.12 node02”即可。
我的建议是,在集群中的每一个节点上,都在/etc/hosts文档中加入所有节点的 IP-主机名 映射关系。也可以再一个节点上修改,后将配置文件复制到其他节点上。解决 无用评论 打赏举报 分享
- 2024-06-12 22:50冷峻的猫的博客 hadoop意外断电服务不可用,所有namenode启动不了,通过修复journal node元数据文件恢复服务
- 2023-03-17 21:351dress的博客 2.切换到hadoop的目录下将logs与tmp文件与内容删除并创建新的logs。3.重新格式化namenode。
- 2024-05-13 20:58申朝先生的博客 在操作Hadoop集群时,务必遵循正确的启动和停止流程,避免异常退出导致的问题。定期检查Hadoop集群的配置文件,确保各项配置正确无误。在进行NameNode格式化之前,务必备份重要数据,以防数据丢失。如果在解决问题...
- 2024-11-22 10:11钮枯禄浪的博客 上课时发现01主节点datanode也没有,在网上找了一圈后选择将tmp删除重新格式化,这里我没有启动集群,重启hadoop后jps发现namenode有了,但是hadoop02和03没有datanode。重启后jps发现从节点有datanode了,这时我...
- 2020-03-18 00:03像素棱镜的博客 问题描述:hadoop集群重启时namenode节点消失 检查发现是core-site.xml文件中定义的hdoop.tmp.dir的文件目录/opt/hadoop-2.10.0/tmp文件目录不存在 解决方法: 1.查看所设目录是否存在(不会自动生成) cd /...
- 2023-08-25 15:21我爱玩泥巴的博客 最近有安装了一次hadoop集群,NameNode启动失败,查看日志,找到以下原因: 遇到的异常: org.apache.hadoop.hdfs.server.common.InconsistentFSStateException: Directory /tmp/hadoop-javoft/dfs/name is in an ...
- 2024-12-14 20:21阿年、嗯啊的博客 服役新节点后,NameNode的web页面无法查看新节点的详细信息!
- 2022-08-30 16:13web18484626332的博客 前景回顾:上一篇文章中我们安装配置完hadoop后启动发现没有namenode节点,而且无法访问对应网站,该篇中将解决上篇的问题。删除文件夹 (hadoop2.7.3/下)的tmp/文件夹里边所有的东西。重新格式化:bin/hadoop ...
- 2023-07-05 23:10本旺的博客 NameNode 作为集群的 Master 节点,需要管理集群中的所有 Slave 节点即 DataNode,负责 DataNode 的心跳状态...注:运行在Hadoop集群的任务都会产生很多个请求,这些所有的请求都打到 NameNode 这儿 (更新元数据目录树)
- 2023-09-25 16:05提醒一下哟的博客 这通常会导致Hadoop集群无法正常运行,影响数据的存储和访问。在操作Hadoop集群时,务必遵循正确的启动和停止流程,避免异常退出导致的问题。定期检查Hadoop集群的配置文件,确保各项配置正确无误。在进行NameNode...
- 没有解决我的问题, 去提问
