我想爬http://skyserver.sdss.org/dr7/en/tools/explore/obj.asp?id=588848900446814264这个网页中的数据
但是我用urllib.request.urlopen打开之后里面的#document里面的东西却没有,不知有没有什么方法爬?

html 中的#document后面的内容为什么爬不下来

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答 默认 最新
- K beasts 2018-10-27 06:38关注
你爬这个页面吧。
http://skyserver.sdss.org/dr7/en/tools/explore/summary.asp?id=0x082c02f481830038&spec=0x011ac9ca7b800000step1: 获取 HTML 源代码
http://skyserver.sdss.org/dr7/en/tools/explore/obj.asp?id=588848900446814264step2: 获取到 frame 的 src 属性,得到新页面链接
http://skyserver.sdss.org/dr7/en/tools/explore/OETOC.asp?id=588848900446814264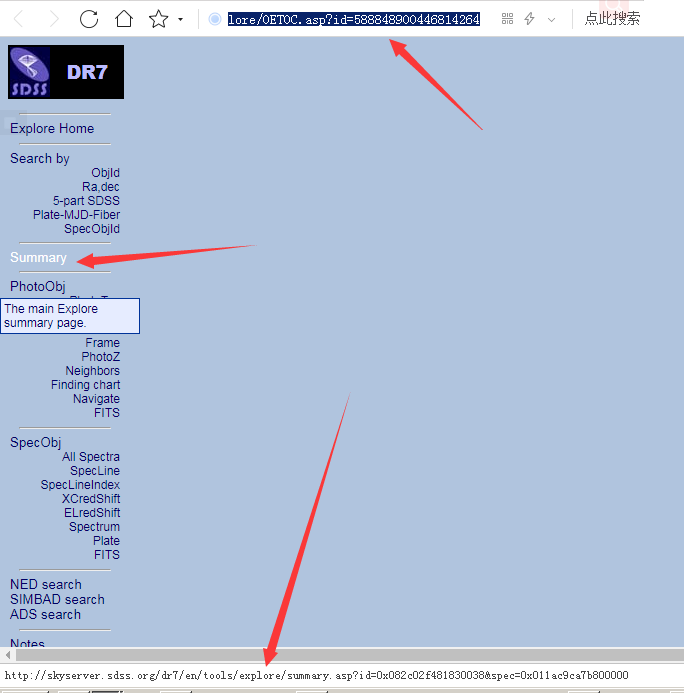
step3: 获取
<tr><td align="left"><a href href属性,最后得到完整的路劲http://skyserver.sdss.org/dr7/en/tools/explore/summary.asp?id=0x082c02f481830038&spec=0x011ac9ca7b800000本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2018-10-27 06:34回答 2 已采纳 你爬这个页面吧。 ``` http://skyserver.sdss.org/dr7/en/tools/explore/summary.asp?id=0x082c02f481830038&s
- 2021-09-28 16:03回答 1 已采纳 你看看数据写入操作(cursor.execute("INSERT INTO mrv2019 VALUES....)是否执行了,然后看看这句话pd.read_sql("SELECT (PortofReg
- 2019-11-10 22:33回答 3 已采纳 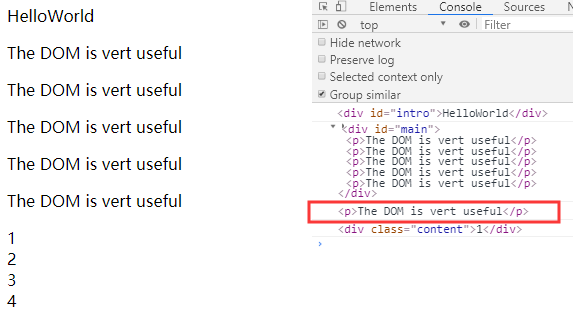 左边是网页显示的内容 右边是console的内容
- 2023-06-08 21:44坚持不懈的大白的博客 总结 下述为AI对于为什么爬虫爬取不到数据的分析: 有很多原因可能导致你的爬虫爬取不到数据,以下是一些常见的原因: 网站防爬虫机制:有些网站会设置反爬虫机制,如验证码、IP限制等。如果你的爬虫被识别为恶意...
- 2022-03-20 22:45回答 2 已采纳 document = MailMerge(template)放 for 循环中试试 for row in sheet.iter_rows(min_row=2, max_row=38,min_col=1
- 2021-05-14 13:23回答 2 已采纳 你的表单是由django后台生成的吧?如果要使用ajax发送post请求,需要加多csrf的参数,或者你在视图函数上面加多装饰器 from django.views.decorators.csrf
- 2022-01-13 10:30回答 6 已采纳 。。。。你这主要是语法错误一共两个。1、var img=document.getElementById(id); 这个请改成var img=document.getElementById(“img”)
- 2023-03-09 21:49qq_繁华的博客 python 爬虫代码
- 2023-04-12 17:40回答 1 已采纳 先转为字符串然后去掉前面两个尖括号,然后在转为json就可以取值了
- 2021-09-24 14:04回答 2 已采纳 可以获取到,因为这个网页中换行时,有的只用了回车符(\r)没有加换行符(\n) 在控制台打印时回车符(\r)与换行符(\n)效果是不一样的。 回车符(\r)在控制台打印中是把光标回到本行的开头,不会换
- 2019-05-07 17:14回答 2 已采纳 你好,我在 test.docx 文件中加了一个批注用来测试。使用下面的代码成功输出了我的批注。 ``` from zipfile import ZipFile from bs4 import
- 2022-01-30 21:28秃顶的博客 Python 网络爬虫与数据采集第1章 序章 网络爬虫基础1 爬虫基本概述1.1 爬虫是什么1.2 爬虫可以做什么1.3 爬虫的分类1.4 爬虫的基本流程1.4.1 浏览网页的流程1.4.2 爬虫的基本流程1.5 爬虫与反爬虫1.5.1 爬虫的攻与防...
- 2021-08-26 14:35回答 5 已采纳 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <
- 2021-08-18 18:44Tr0e的博客 本文将学习记录下如何使用 Python 脚本将 CSDN 博文自动以 HTML、PDF 两种格式的文件保存到本地。 单篇保存 先来看看如何对指定的单篇文章进行本地保存和格式转换。 脚本编写 1、脚本需要导入以下模块: import ...
- 2023-06-13 16:50TTTALK的博客 python爬虫资源抓取--urllib/requests/requests-html、正则表达式、数据解析-Beautiful Soup/lxml/selectolax、自动化爬虫--selenium、爬虫框架--Scrapy/pyspider、模拟登录与验证码识别、autoscraper
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 用百度飞将的paddleyolo库里的yolov7训练自己数据集
- ¥15 Saber里如何查看磁芯的磁通密度
- ¥25 关于下拉菜单、数据库、关联选项的问题
- ¥15 STM32 串口DMA同时收发丢字节
- ¥15 SBML检验显示文档无效改怎么修改?
- ¥15 微信小程序的爬虫问题
- ¥15 使用matlab解决如下问题·
- ¥15 招募一个精通Verilog的指导我完成单周期cpu的仿真和下板子
- ¥15 安卓QQ协议判断协议软
- ¥15 Office2016如何使用公司域账户登录?