
'''
代码
'''
import time
import random
myList=[]
count=0
def decorate(function):
def inner(*args):
start=time.time()
function(*args)
end=time.time()
print(end-start)
return function
return inner
def QuickSort(myList,start,end):
if start
i,j=start,end
base=myList[i]
while i
while(i=base):
j=j-1
myList[i]=myList[j]
while(i<j) and (myList[i]<=base):
i=i+1
myList[j]=myList[i]
print(myList)
myList[i]=base
QuickSort(myList,start,i-1)
QuickSort(myList,j+1,end)
return myList
for num in range(0,1000):
myList.append(random.randint(0,1000))
myList=random.sample(myList,5)
@decorate
def quick():
QuickSort(myList,0,len(myList)-1)
#myList.sort()
quick()
'''
结果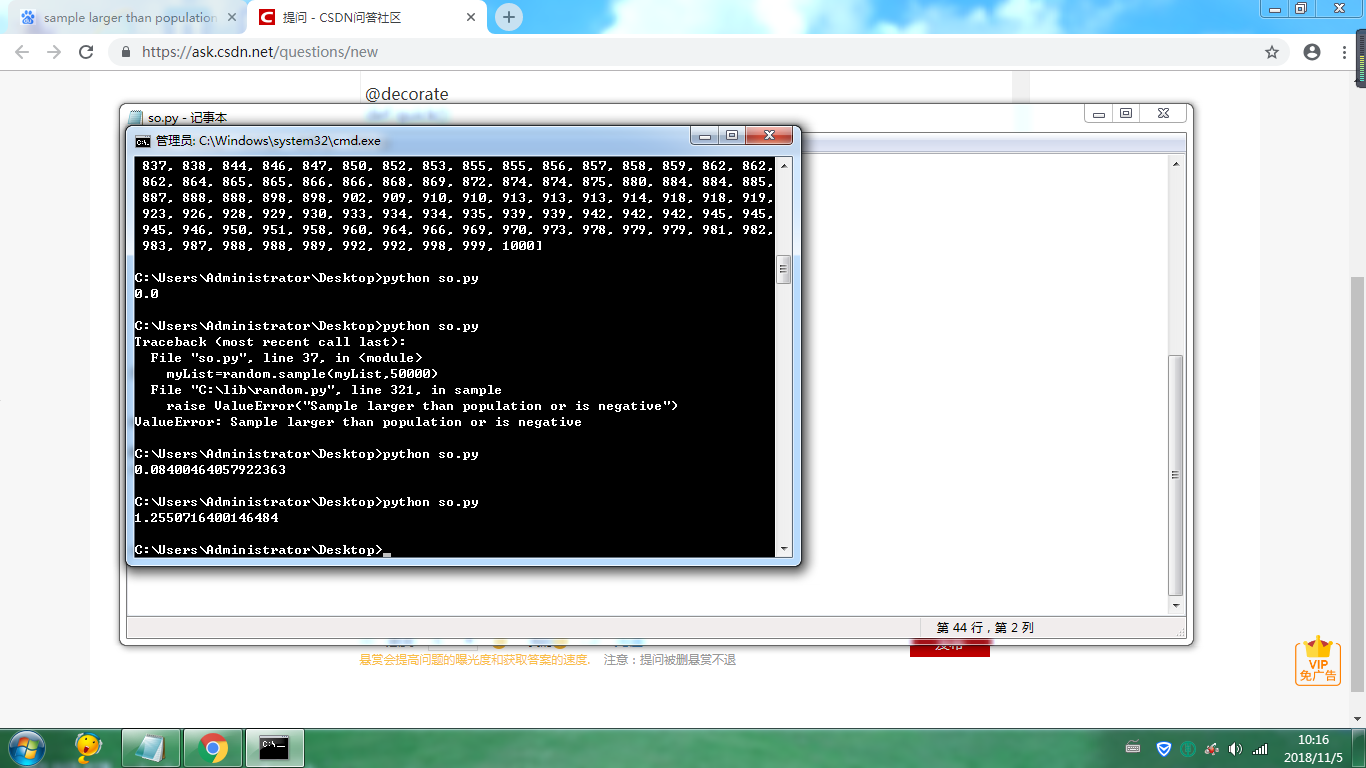
'''
'''
提问:为什么快速排序的算法速度会比python自带的sort()执行的时间慢,而且慢的很多?
'''



