




我用mapreduce做单词的统计
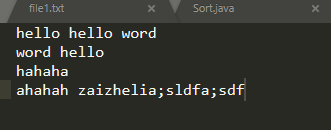
数据:
map程序
public class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Text word = new Text();
LongWritable one = new LongWritable(1);
//将Text转为String
String line = value.toString();
//分词
String[] wordArr = line.split("\\s+");
word.set(wordArr[0]);
//将词的次数放入context
context.write(word ,one);
}
}
reduce程序:
public class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
Long sum = 0L;
for(LongWritable value:values){
sum += value.get();
}
context.write(key,new LongWritable(sum));
}
}
结果: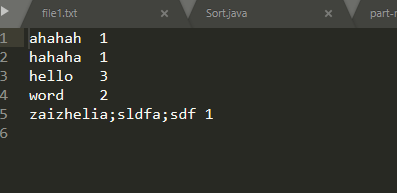
我只想统计第一列的词汇
想要的结果是
word 1
hello 1
hahha 1
ahaha 1
到底哪里出错了
















