
post地址:http://192.168.244.130:8998/batches
body:
{"file":"hdfs://192.168.244.130:9000/mdjar/modelcall-2.0.jar","className":"cn.com.cnpc.klmy.common.WordCount2"}
报错:xxx.ClassNotFoundException: cn.com.cnpc.klmy.common.WordCount2
请教各位大咖,我到底是哪里错了?大家有什么解决方案或者建议吗?望各位大咖不吝赐教!跪谢!
截图如下所示,图一:使用postman发送的截图,图二:livy的管理页面
图一:使用postman发送的截图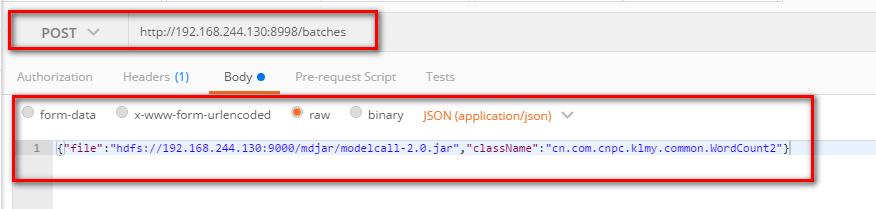
图二:livy的管理页面
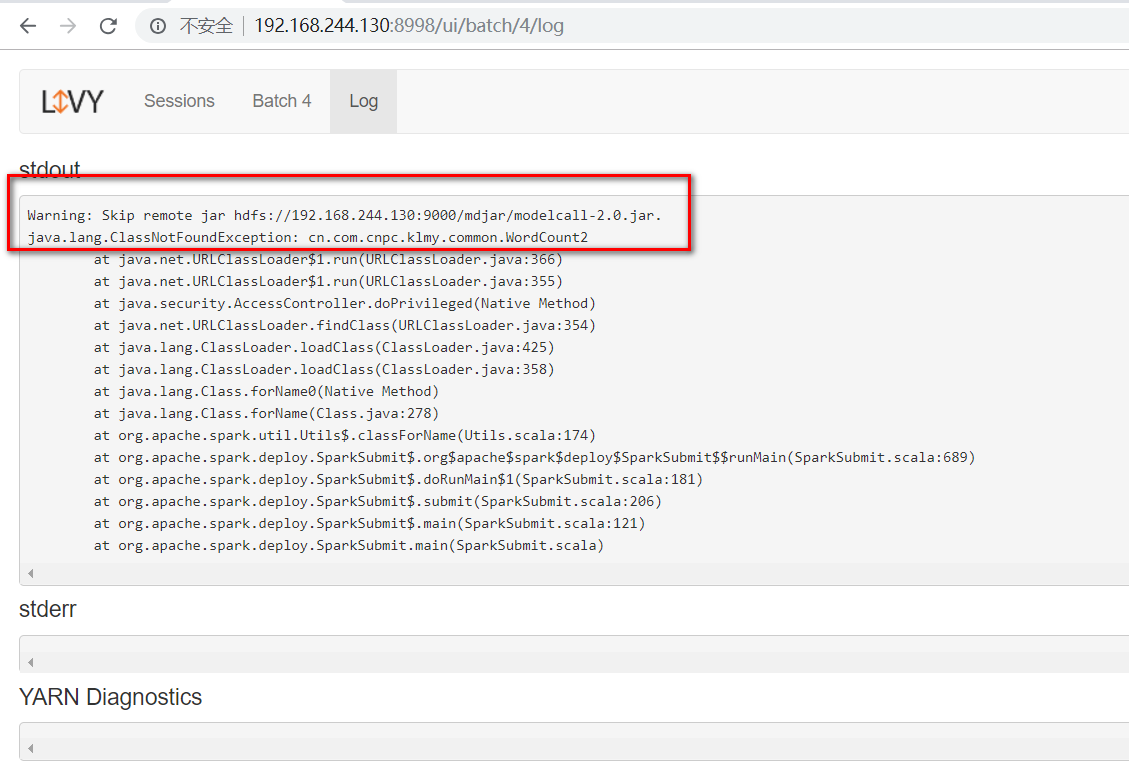
注:在linux服务使用spark-submit提交成功:
./spark-submit --master spark://192.168.244.130:7077 --class cn.com.cnpc.klmy.common.WordCount2 --executor-memory 1G --total-executor-cores 2 /root/modelcall-2.0.jar





