

import json
import urllib.error, urllib.request, urllib.parse
import http.cookiejar
s = requests.Session()
class Login(object):
def init(self):
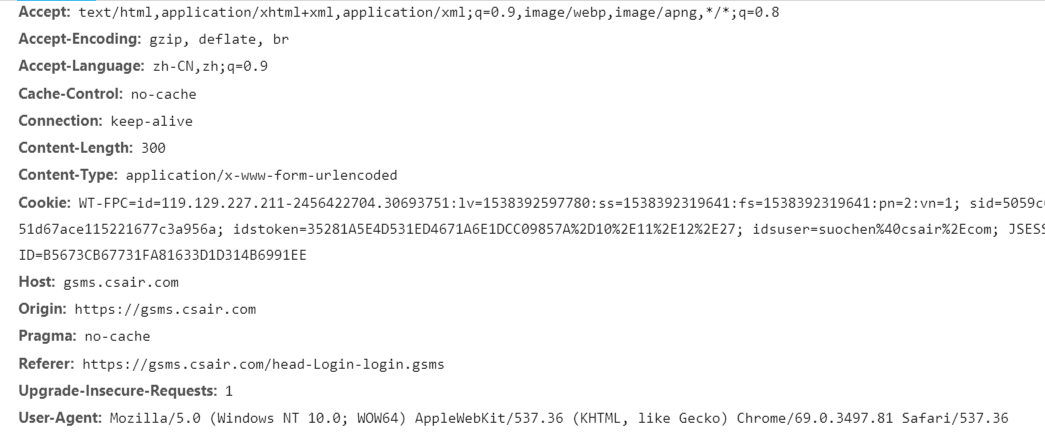
self.headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36',
'host':'gsms.csair.com',
'Origin':'https://gsms.csair.com',
'referer': 'https://gsms.csair.com/head-Login-login.gsms'
}
self.login_url='https://gsms.csair.com/head-Login-login.gsms'
self.post_url='https://gsms.csair.com/j_spring_security_check'
self.logined_url='https://gsms.csair.com/main_defaultmain.gsms'
self.ajax_url='https://gsms.csair.com/ghc-ghchome-GhcHome-getUserInfo.gsms'
def get_code(self):
codeurl = 'https://gsms.csair.com/captcha.img'
valcode = requests.get(codeurl)
f = open('valcode.jpg', 'wb')
f.write(valcode.content)
f.close()
code = input('请输入验证码:')
return str(code)
def login(self):
post_data={
'j_username':'228186',
'j_password':'*******',
'inputRand':self.get_code()
}
response = s.post(self.login_url, data=post_data, headers=self.headers)
if response.status_code== 200:
print('s')
response = s.get(self.logined_url,headers=self.headers)
if response.status_code== 200:
print(response.text)
if name== "__main__":
login=Login()
login.login()







