就这种不知道是js加载的还是什么,通过某种技术加密的爬虫就没办法解决了,请教各位大神指教下这种怎么解决,能给个代码示例就最好了,谢谢

就这种不知道是js加载的还是什么,通过某种技术加密的爬虫就没办法解决了,请教各位大神指教下这种怎么解决,能给个代码示例就最好了,谢谢
 分享
分享
哎,都被你们这帮人爬坏了,想想也是心塞。
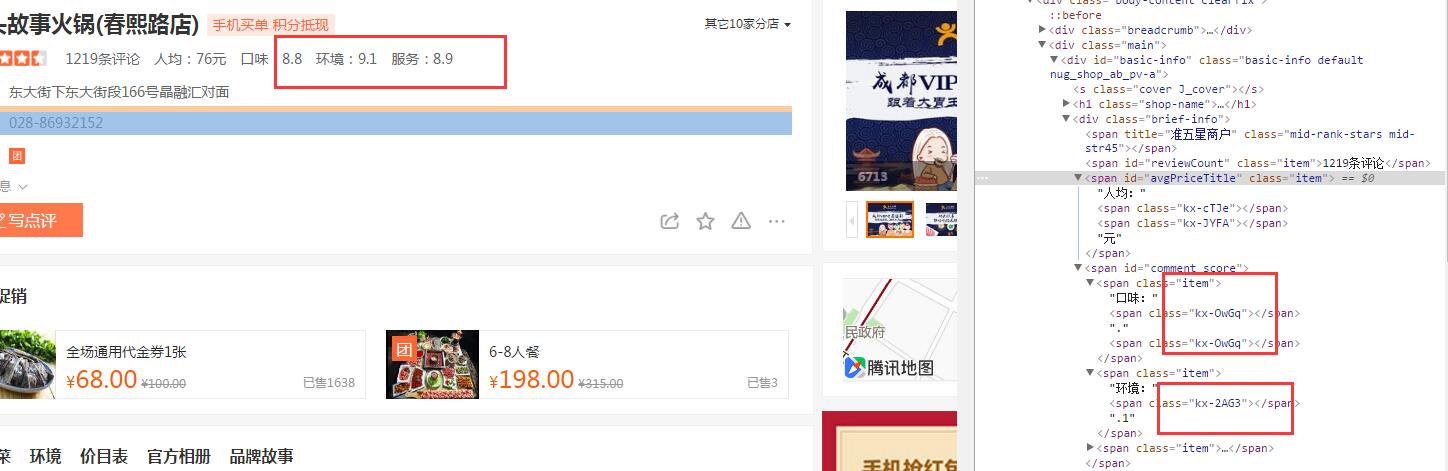
其实为了反爬,大众点评也是下了很大功夫,但是刚刚我看了一下,还是不到位。它是采用的类似于图片一样的class代替原先的明文,这样可以加大你们分析数据的障碍。
不仅仅是你框起来的三个,上面所有的数字都进行了相同的处理。我列一下今天的规律:
0 ----> kx-vAWZ
1 ---->
2 ----> kx-ojVa
3 ----> kx-ckCO
4 ----> kx-kjJp
5 ----> kx-3TvL
6 ----> kx-JYFA
7 ----> kx-cTJe
8 ----> kx-OwG9
9 ----> kx-2AG3
总结:
1.其中1没有进行处理,我猜测是因为处理之后的数字间距会失衡,导致不能进行编码。所以需要注意一下这种特殊情况的处理
2.这种规律不确定有效性有多长,所以你还需要专门添加定时任务检查上面的对应关系,一旦检查出来不匹配,立即更新策略
3.据我了解点评网检测到对方是爬虫后,并不一定会直接IP添加到黑名单,会给你发一坨假数据,所以第二步的操作必须要做
分享




