关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
FixedStarHaHa
2018-11-25 14:37
采纳率: 50%
浏览 796
首页
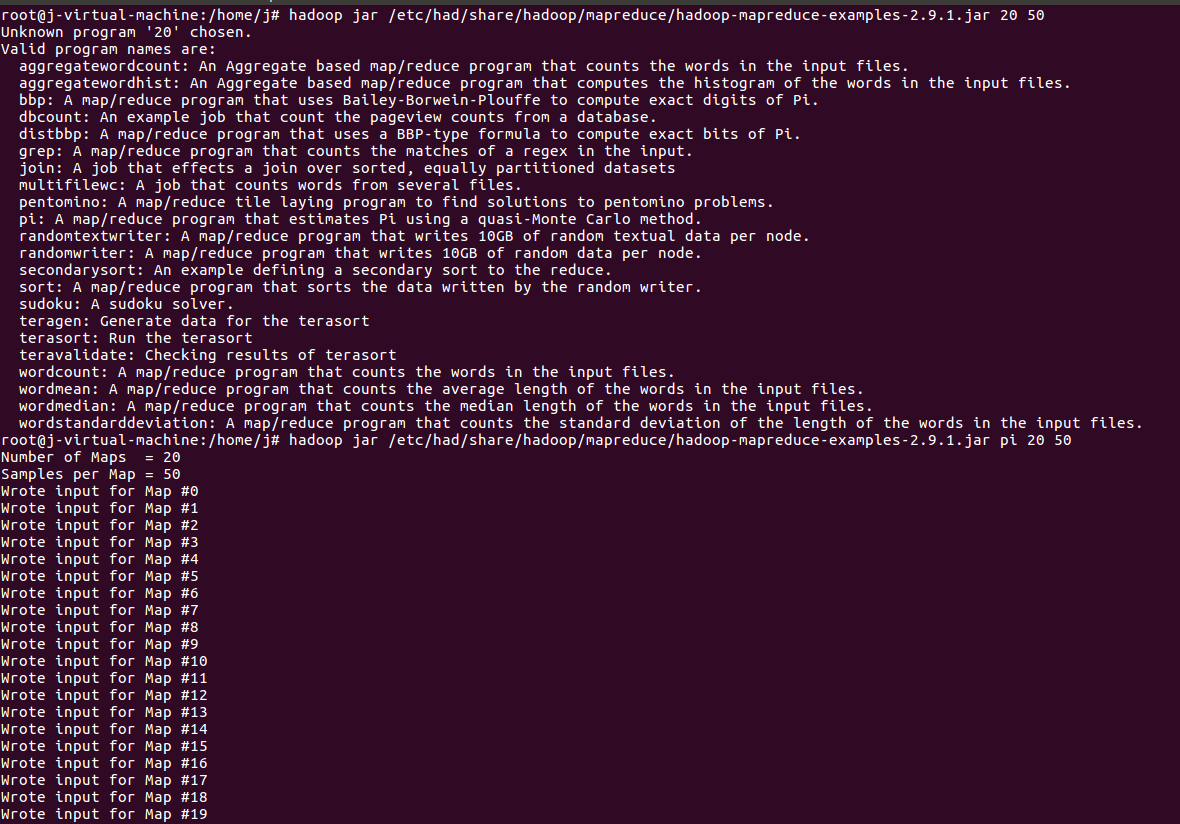
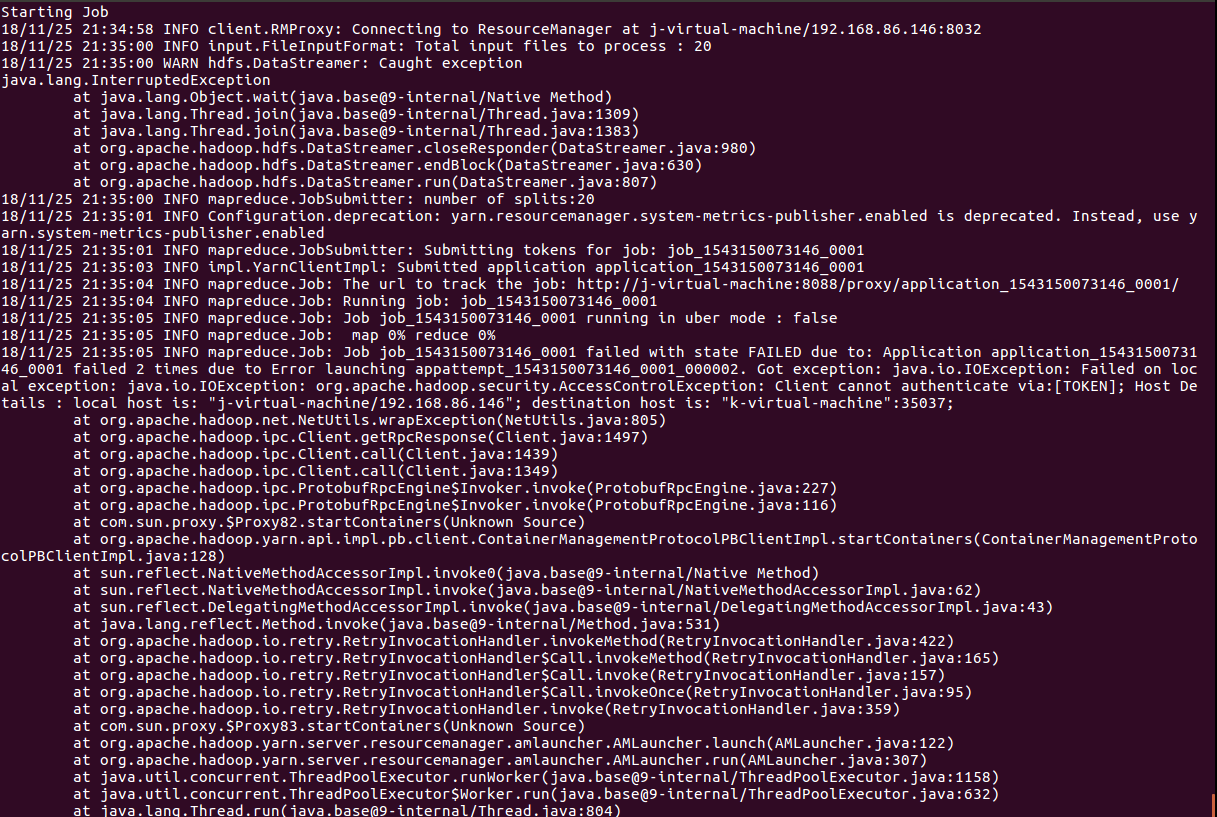
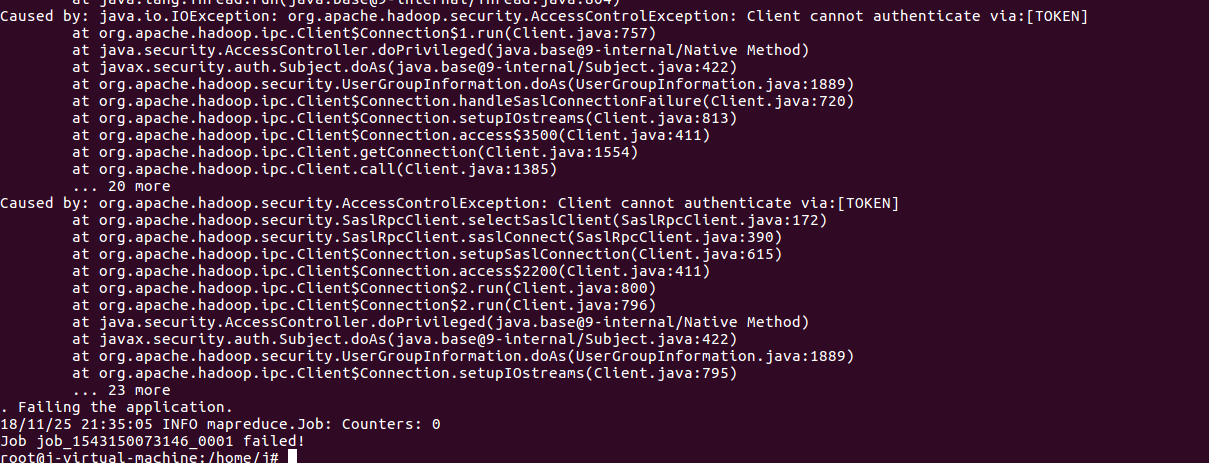
hadoop初学者,集群建立成功,执行圆周率例子,出现如下错误,请大神们帮忙看下
hadoop
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
结题
收藏
举报
2
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
devmiao
2018-11-25 15:53
关注
https://www.cnblogs.com/xiaoxiao5ya/p/da686507959026b16d479ca07876bc04.html
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(1条)
向“C知道”追问
报告相同问题?
提交
关注问题
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告


 分享 分享
分享 分享
