
Yahoo! Streaming Benchmark简介
Yahoo! Streaming Benchmark是Yahoo的一个团队在2015年对当前热门的流式计算平台:Sparking Streaming, Storm和Flink开发的一个基准测试系统。
该系统是当时第一个将这三个流式计算平台在模拟真实应用场景下的基准测试,对后面的基准测试系统的发展有重要的意义。
该系统详细的介绍见:https://yahooeng.tumblr.com/post/135321837876/benchmarking-streaming-computation-engines-at。
Github地址:https://github.com/yahoo/streaming-benchmarks。
问题描述
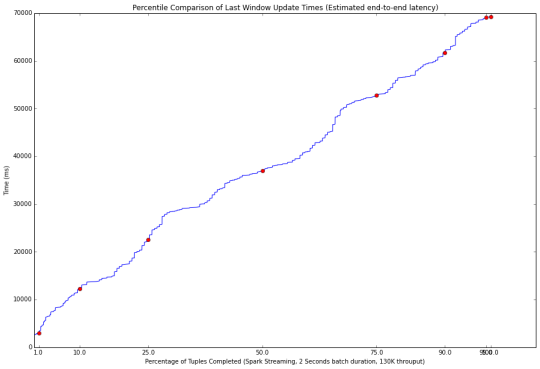
在使用该基准测试系统进行运行之后,会产生两个结果文件:seen.txt,updated.txt。其中记录的相关的测试结果信息,但对这两个文件中数据的含义存在困惑。相似的问题在Github中仍存在,但无人解答:https://github.com/yahoo/streaming-benchmarks/issues/22。
因此,如何理解这个基准测试的信息,并且如何使用这些数据绘制出如下统计图(该图是该系统开发人员进行给出的):
感谢你的回答!!!





