假如我现在要批量提交很多数据保存到mysql数据库,我如何做到一边提交一边
检测数据库是否存在,如果存在的话就在数据库某字段加一。
sql语句如何实现
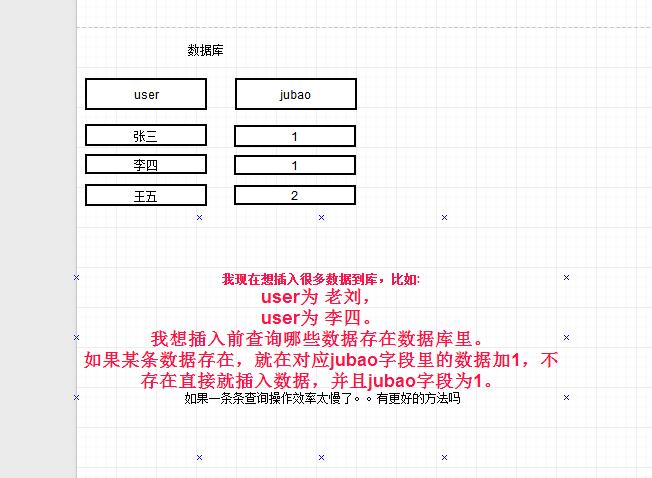

假如我现在要批量提交很多数据保存到mysql数据库,我如何做到一边提交一边
检测数据库是否存在,如果存在的话就在数据库某字段加一。
sql语句如何实现
 分享
分享
使用insert update复合sql语句
例如你这里,insert into t(user, jubao) values( 'username', 1) on duplicate key update jubao = jubao + 1
前提是你需要保证user字段是唯一性,如果不是
alter table t add unique key(user);
分享


