我是python3.6的版本,超级新手,望大神指教。
在爬取网页数据时,print(results[0].text)可以索引出对应文本,但是取全列表时就出现错误,具体情况如下图,求大神教教我吧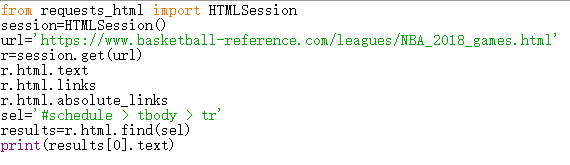
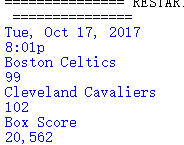
当我改成results[0:].text时,就出现问题了。如果我想获取全列表文本,应该怎么做呢?



我是python3.6的版本,超级新手,望大神指教。
在爬取网页数据时,print(results[0].text)可以索引出对应文本,但是取全列表时就出现错误,具体情况如下图,求大神教教我吧
当我改成results[0:].text时,就出现问题了。如果我想获取全列表文本,应该怎么做呢?
 分享
分享
for item in results:
print(item.text)



