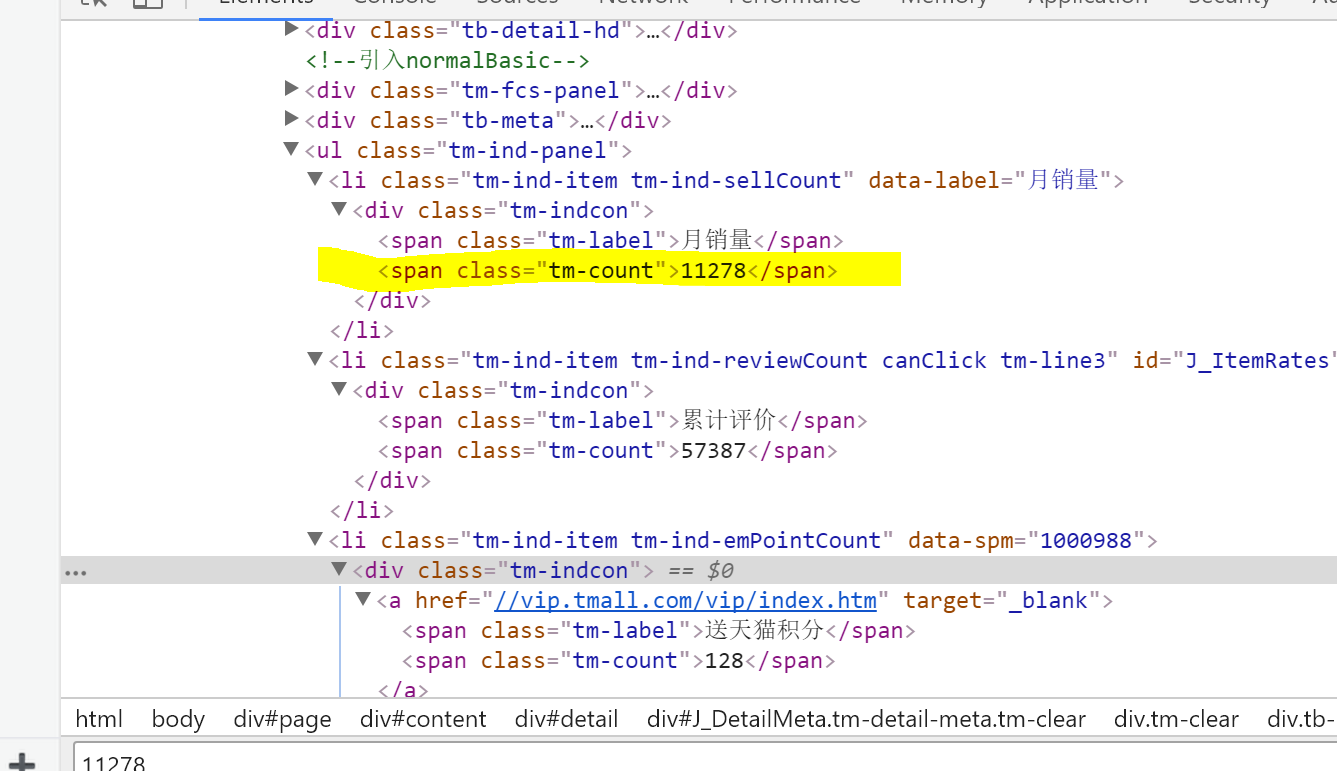
如题:我使用selector.xpath('//*[@class="tm-count"]/text()')
来爬的时候,会爬到最下方的128
我想要爬到11278这个数据
这个selector.xpath('')应该怎么写呢

如题:我使用selector.xpath('//*[@class="tm-count"]/text()')
来爬的时候,会爬到最下方的128
我想要爬到11278这个数据
这个selector.xpath('')应该怎么写呢
 分享
分享
←如果以下回答对你有帮助,请点击右边的向上箭头及采纳下答案
刚测试了一下,天猫有浏览器内核检测机制,能检测到你使用的是selenium,大部分数据不正常加载(不用无头模式可以看到),且频繁显示登录框要求登录,在登录页面又出现滑块验证,滑块在selenium无法通过验证(人工操作也是错误),所以一定要用selenium去爬取,只能通过正常的在
浏览器中登录后,将登录的cookies复制下来,然后在加载到selenium完成登录后才可以看到销量,才可以爬取到对应的数据
def tm():
driver = webdriver.Chrome()
driver.get(url='https://login.tmall.com/')
cookies='你登录的cookies'
nml=re.findall(' (.*?)=',cookie)
val=re.findall('=(.*?);',cookie)
for i in range(0,20):
cookie_dict = {
"domain": ".taobao.com", # 火狐浏览器不用填写,谷歌要需要
'name': nml[i],
'value': val[i],
"expires": "",
'path': '/',
'httpOnly': False,
'HostOnly': False,
'Secure': False}
driver.add_cookie(cookie_dict)
print ("ok")
driver.get(url='https://detail.tmall.com/item.htm?id=530559465281')
driver.implicitly_wait(30)
price= driver.find_element_by_xpath("//div[@id='J_DetailMeta']/div/div/div/ul/li/div/span[2]").text
print(price)
driver.quit()
tm()
这种方法在爬虫里不合适,在频繁的采集之后,cookies的失效,要求重新登录
分享


