在flink目录执行./bin/yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024时,启动的时候报2018-12-16 16:01:42,879 ERROR org.apache.flink.yarn.cli.FlinkYarnSessionCli - Error while running the Flink Yarn session.
org.apache.flink.client.deployment.ClusterDeploymentException: Couldn't deploy Yarn session cluster
at org.apache.flink.yarn.AbstractYarnClusterDescriptor.deploySessionCluster(AbstractYarnClusterDescriptor.java:423)
at org.apache.flink.yarn.cli.FlinkYarnSessionCli.run(FlinkYarnSessionCli.java:607)
at org.apache.flink.yarn.cli.FlinkYarnSessionCli.lambda$main$2(FlinkYarnSessionCli.java:810)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1692)
at org.apache.flink.runtime.security.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41)
at org.apache.flink.yarn.cli.FlinkYarnSessionCli.main(FlinkYarnSessionCli.java:810)
Caused by: org.apache.flink.yarn.AbstractYarnClusterDescriptor$YarnDeploymentException: The YARN application unexpectedly switched to state FAILED during deployment.
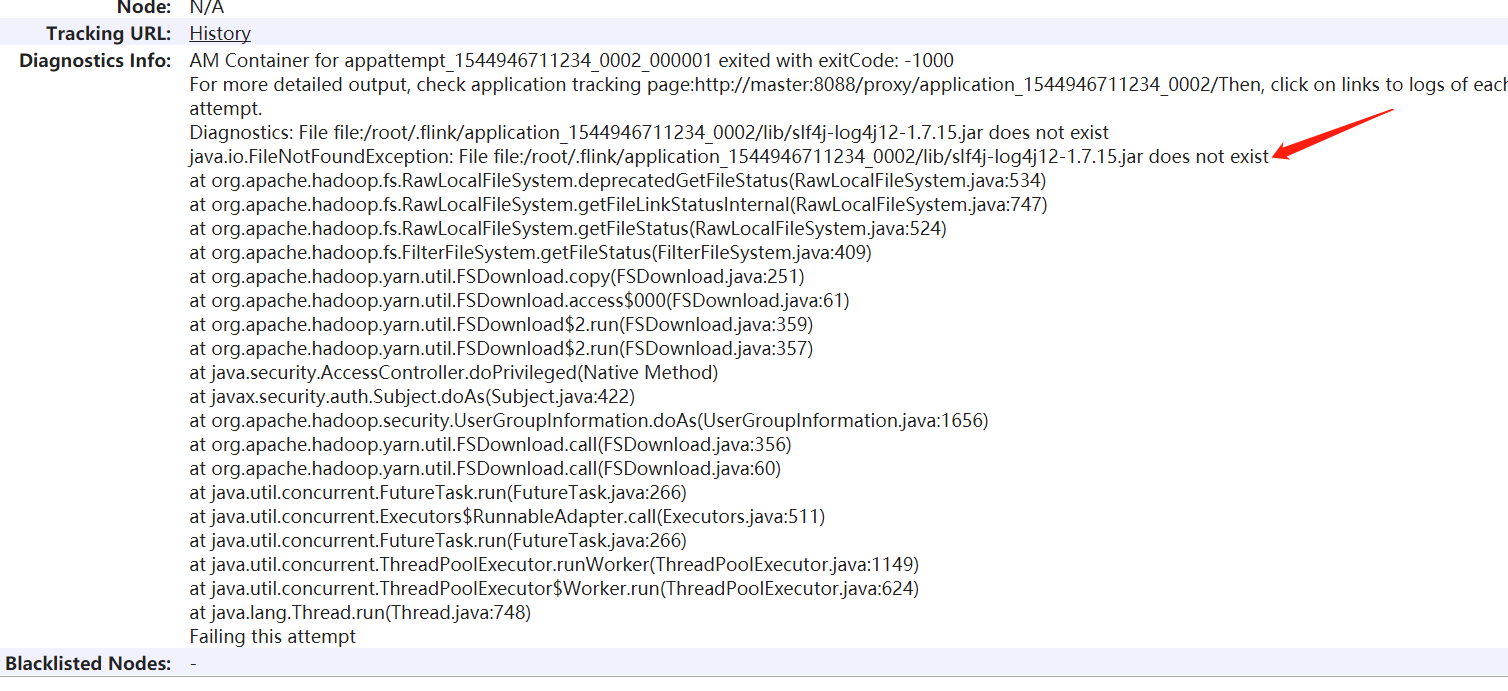
Diagnostics from YARN: Application application_1544946711234_0002 failed 1 times due to AM Container for appattempt_1544946711234_0002_000001 exited with exitCode: -1000
For more detailed output, check application tracking page:http://master:8088/proxy/application_1544946711234_0002/Then, click on links to logs of each attempt.
Diagnostics: File file:/root/.flink/application_1544946711234_0002/lib/slf4j-log4j12-1.7.15.jar does not exist
java.io.FileNotFoundException: File file:/root/.flink/application_1544946711234_0002/lib/slf4j-log4j12-1.7.15.jar does not exist
at org.apache.hadoop.fs.RawLocalFileSystem.deprecatedGetFileStatus(RawLocalFileSystem.java:534)
flink在hadoop yarn运行出错,报相应的jar找不到(self4j)

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新
- 普通网友 2018-12-16 08:34关注
在/root/.flink/ 下没有任务东西;
//经排查是没有export hadoop的环境变量,只是添加了变量;export后就好了;
解决 无用评论 打赏举报 分享
- 2025-07-14 17:59码字的字节的博客 当YARN在2012年随Hadoop 2.0问世时,它最初被定位为"MapReduce的资源调度替代方案"。但经过十余年发展,这个曾被戏称为"Yet Another Resource Negotiator"的组件,已经演变为大数据生态系统的中枢神经系统。根据...
- 2023-12-02 10:17这啥名啊的博客 下载链接为上传到hdp01上,并复制到/var/www/html下。
- 2024-12-02 17:45风卷残尘的博客 datax在yarn上运行
- 2024-06-24 14:38林晞的博客 64 x86_64 x86_64 GNU/Linu 1.2 系统镜像文件 CentOS-7-x86_64-Minimal-2009.iso 1.3 主机准备 主机名 主机IP 主机配置 服务分布 painon01 192.168.199.13 2c、8g hadoop,hive,flink,paimon painon02 192.168.199...
- 2025-05-07 15:56光子AI的博客 随着全球数据量以每年 40% 的速度激增(IDC 预测),传统集中式数据处理架构在存储容量、计算性能和成本效率上均面临瓶颈。Hadoop 作为 Apache 开源项目的核心,提供了一套分布式、高容错、可扩展的解决方案,成为...
- 2025-06-23 00:47AGI大模型与大数据研究院的博客 本文旨在为大数据开发者和架构师提供关于Hadoop YARN资源管理系统的全面指南。我们将深入探讨YARN的架构设计、核心概念、工作原理以及实际应用场景,帮助读者掌握YARN集群的配置、优化和故障排查技能。本文首先介绍...
- Hayasaka._的博客 启动完成 容器相当于一个虚拟机,在bash界面直接操作即可 - 自启动项目: SSH Hadoop zookeeper Spark Hbase Flink Kafka MySQL Phoenix Query Server 以上项目已配置自启动,无需再次运行启动命令 其他项目...
- 2023-05-18 20:42研发咨询顾问的博客 下面是有默认的配置的,删除掉,在插入,不要重复配置,会出错,也不乱设置,不然程序一直运行不会停止,测试过发现这个情况,所以cpu核算不要乱写,否则工作节点会一直申请资源。首先hadoop集群安装起来,和之前...
- 2021-10-09 12:53王知无(import_bigdata)的博客 点击上方蓝色字体,选择“设为星标”回复”面试“获取更多惊喜 一 .前言官方发布了Flink1.14版本,但是遗憾的是,中文官网中的案例和资料还都是基于很古老的版本。所以大家照着官网资料...
- 2022-06-29 18:09Bourne-Wang的博客 Download flink from apache{:target=“_blank”}, extract to /opt/module .
- 没有解决我的问题, 去提问
