关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
zzzzls~
2018-12-27 20:55
采纳率: 100%
浏览 2825
首页
Python
已采纳
Python Requests 保存 Cookie 到本地发生的问题
python
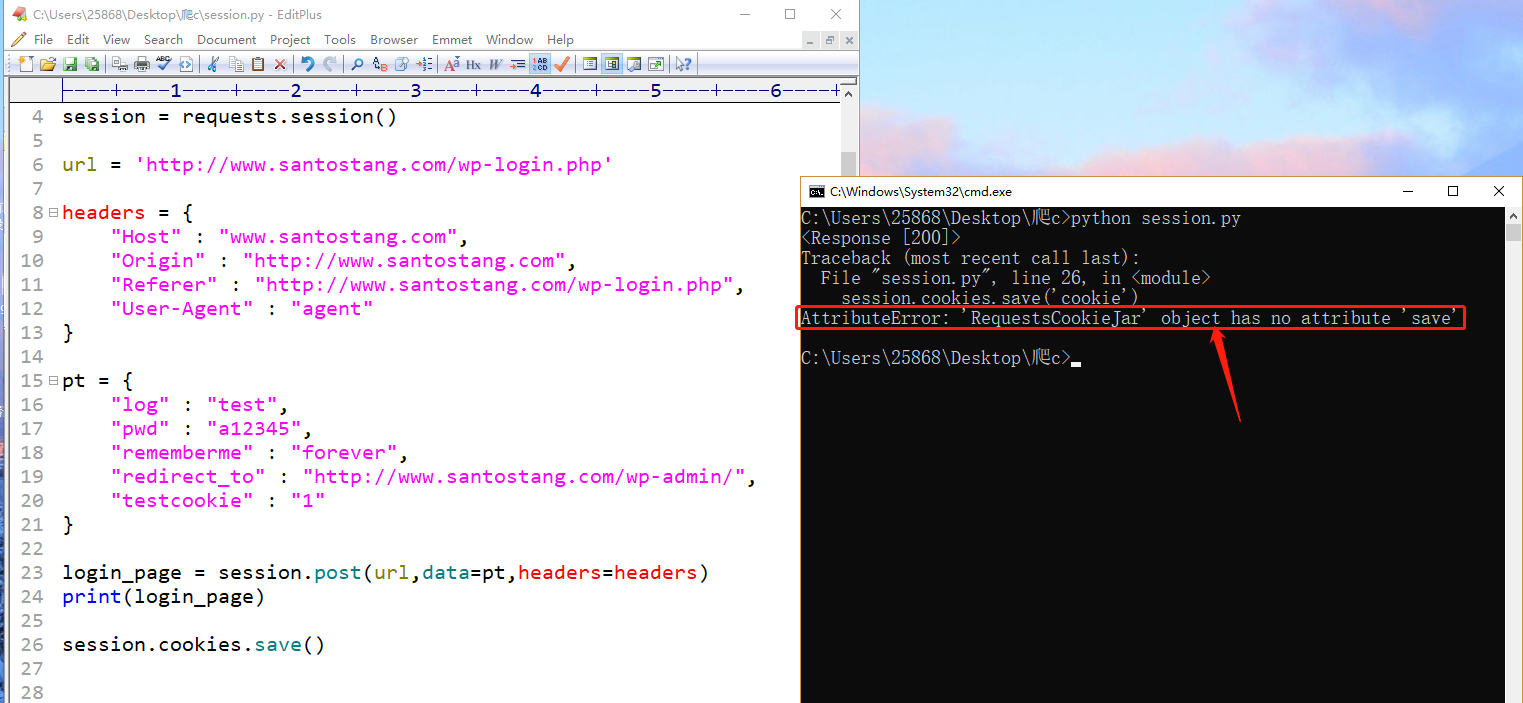
各位大佬 , 执行
session.cookies.save()
这句代码时 , 提示 如上错误
小白求解
谢谢
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
结题
收藏
举报
2
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
devmiao
2018-12-27 14:39
关注
没有save这个方法
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(1条)
向“C知道”追问
报告相同问题?
提交
关注问题
Python
Requests
使用
Cookie
[代码]
2025-11-13 07:26
Cookie
是服务器发送到用户浏览器并
保存
在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上。使用
Python
Requests
库可以非常方便地处理
Cookie
,实现会话状态的维护、用户认证等...
Python
如何通过
requests
模块实现
Cookie
登录
Python
源码
2023-11-09 16:02
Python
如何通过
requests
模块实现
Cookie
登录
Python
源码
Python
如何通过
requests
模块实现
Cookie
登录
Python
源码
Python
如何通过
requests
模块实现
Cookie
登录
Python
源码
Python
如何通过
requests
模块实现
Cookie
登录 ...
python
cookie
反爬处理的实现
2020-12-16 20:36
Cookie
s的处理 作用 ...如果在请求的过程中产生了
cookie
,如果该请求使用session发起的,则
cookie
会被自动存储到session中. 案例 爬取雪球网中的新闻资讯数据:https://xueqiu.com/ #获取一个sessi
Python
3
requests
库的
cookie
s本地
保存
与读取
2021-08-25 10:21
fishvi的博客
保存
cookie
s import
requests
import http.
cookie
jar session =
requests
.Session() session.
cookie
s = http.
cookie
jar.LWP
Cookie
Jar(filename='
cookie
s.txt') response = session.post(url, data) if response....
【
Python
爬虫教程】第7篇-
requests
模块的
cookie
s
保存
和使用
2024-07-15 14:40
码农小黑的日志的博客
保存
cookie
s是避免每次都登录获取权限,一遍权限是有过期时间的,不需要每次重复登录,可以将
cookie
s
保存
起来,用的时候再加载。适用于多机器并发式爬取数据或者抢票等功能。
Python
+
Requests
模块添加
cookie
2025-02-07 21:45
自动化测试薰儿的博客
cookie
_dict = {"login_name":"admin"} #
cookie
做一个变量,然后再请求中使用
cookie
s。# 添加
cookie
绕过登录phpwind论坛。# 1.手动打开论坛获取登录后的
cookie
。# session添加
cookie
。对于某些网站,登录然后从...
python
requests
cookie
的获取和使用
2022-10-03 00:12
阿龙的代码在报错的博客
python
request
cookie
的获取和使用
解决
Python
中
requests
库的session无法
保存
cookie
的
问题
2021-11-10 11:26
adorable_的博客
当我们在使用
Python
的
requests
库做接口自动化时,我们都知道只要使用session =
requests
.session()就会自动
保存
cookie
但当我在做公司的接口自动化项目时,发现
保存
的
cookie
不生效,通过请求登录接口后打印...
python
requests
cookie
jar,
Python
requests
模块
cookie
实例解析
2021-04-26 17:59
少横的博客
cookie
并不陌生,与session一样,能够让...在
python
requests
模块-session中,我们知道了
requests
中的session对象能够在请求之间保持
cookie
,它极大地方便了我们去使用
cookie
。当我们想设置方法级别中的请求时,可...
Python
:
保存
b站的
cookie
到本地
2024-06-12 09:29
knighthood2001的博客
'w') as f: f.write(str(session.
cookie
s.get_dict())) break time.sleep(1) 接着我们采用死循环,每隔一秒去检查一下,你那个二维码是否扫码了,如果扫码了,就会
保存
其中的
cookie
到本地
。 小结 最后
保存
的
cookie
...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告

 分享
分享



