这几天在学习xpath的时候发现无法正确定位,返回的div_list都是空列表,但response信息是有正确返回的。可是怎么检查也没发现错误,希望大佬们麻烦看看,谢谢。
python版本3.6.
def select_html(self,response): #筛选网页信息
html = etree.HTML(response)
#分组
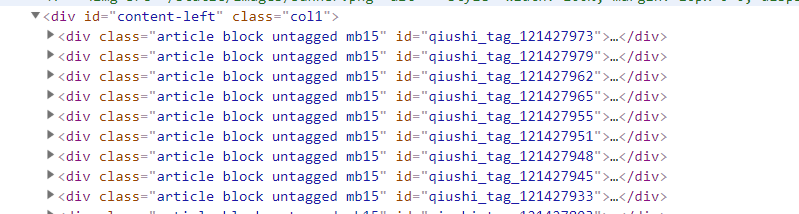
div_list = html.xpath("//div[@id='content-left']/div")
print(div_list)
for line in div_list:
data = {}
data['content'] = line.xpath(".//div[@class='content']/span/text()")
data['stats'] = line.xpath(".//div[@class='stats']/span[@class='stats-vote']/i/text()")
data['comment_number'] = line.xpath(".//span[@class='stats-comments']/a/i/text()")
data['img'] = 'https:'+ line.xpath(".//div[@class='thumb']/a/img/@src")
爬的是糗事百科的内容,下面是糗事百科的html截图: