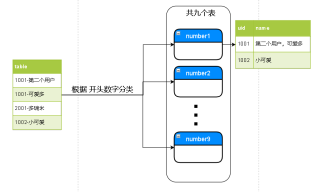
针对这个问题,我可以给出以下的解决方案:
- 创建number1~9个表,表结构如下:
CREATE TABLE number1 (
uid int UNSIGNED NOT NULL,
name varchar(200) NOT NULL,
PRIMARY KEY(uid)
)ENGINE=InnoDB CHARSET=utf8;
同理创建number2~9个表。
- 对源数据进行分类,可以使用以下语句:
INSERT INTO number1(uid,name) SELECT SUBSTRING_INDEX(number, '-', 1),
SUBSTRING_INDEX(number, '-', -1) FROM table1 WHERE number LIKE '1%';
同理,使用类似的语句进行分类存储。
- 将元数据分割开存储,在插入语句中使用SUBSTRING_INDEX函数进行拆分。如果遇到uid相同的数据,则使用CONCAT_WS函数将name字段合并。
INSERT INTO number1(uid,name) SELECT SUBSTRING_INDEX(number, '-', 1),
IFNULL(CONCAT_WS(',',n1.name,n2.name),'') AS name FROM table1
LEFT JOIN number1 AS n1 ON SUBSTRING_INDEX(table1.number, '-', 1)=n1.uid
LEFT JOIN number1 AS n2 ON SUBSTRING_INDEX(table1.number, '-', 1)=n2.uid AND n1.name<>n2.name
WHERE table1.number LIKE '1%' AND n1.uid IS NOT NULL;
同理,使用类似的语句进行拆分存储。在JOIN表的过程中,通过判断uid相同,但name不同时,使用CONCAT_WS将多个name进行合并。
总结:
以上是基于Mysql的解决方案,对于大量数据的处理方案一定要考虑到语句的精简以及效率的问题,可以在实际应用中进行针对性的优化。