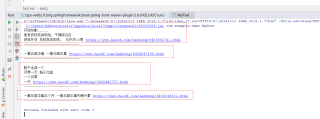
现有一个文本 txt 文件,内容如下:
患有抗核抗体阳性,干燥综合征
现在怀孕 抗核抗体阳性, 已怀孕10周 https://www.haodf.com/kanbing/6483842721.html
一氧化碳中毒 一氧化碳中毒 https://www.haodf.com/kanbing/6484847288.html
脑干出血一个
月零一天 脑干出血
一个月零
一天 https://www.haodf.com/kanbing/6482442757.html
一氧化碳中毒半个月 一氧化碳中毒失眠头晕 https://www.haodf.com/kanbing/6484746310.html
问题:将文本中没有出现 url 且相邻的字符串与其下一个有 url 的字符串拼接在一起,顺序不变返回一个新文件?
pattern = r'https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+/[a-z]{7}/[0-9]+.html'
spo = re.findall(pattern, line, re.S | re.M)
思路:遍历文本字符串,并判断 spo 是否在字符串中,如果没有则加入列表并与下一个 url 的字符拼接在一起,组成一个” 问题 + 空格 + url“格式的文本。
菜鸡了,实在想不出来,有没有大佬帮忙的?
最终完成效果如下:
患有抗核抗体阳性,干燥综合征现在怀孕 抗核抗体阳性, 已怀孕10周 https://www.haodf.com/kanbing/6483842721.html
一氧化碳中毒 一氧化碳中毒 https://www.haodf.com/kanbing/6484847288.html
脑干出血一个月零一天 脑干出血一个月零一天 https://www.haodf.com/kanbing/6482442757.html
一氧化碳中毒半个月 一氧化碳中毒失眠头晕 https://www.haodf.com/kanbing/6484746310.html