import os
os.environ['CUDA_VISIBLE_DEVICES']='1'
class CycleGAN():
def __init__(self):
# Input shape
self.img_rows = 40
self.img_cols = 40
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
# Calculate output shape of D (PatchGAN)
patch = int(self.img_rows / 2**3)
self.disc_patch = (patch, patch, 1)
# Number of filters in the first layer of G and D
self.gf = 32
self.df = 64
# Loss weights
self.lambda_cycle = 10.0 # Cycle-consistency loss
self.lambda_id = 0.1 * self.lambda_cycle # Identity loss
optimizer = Adam(0.002, 0.5)
# Build and compile the discriminators
self.d_A = self.build_discriminator()
self.d_B = self.build_discriminator()
self.d_A.compile(loss='mse',
optimizer=optimizer,
metrics=['accuracy'])
self.d_B.compile(loss='mse',
optimizer=optimizer,
metrics=['accuracy'])
# Build the generators
self.g_A2B = self.build_generator()
self.g_B2A = self.build_generator()
# Input images from both domains
img_A = Input(shape=self.img_shape)
img_B = Input(shape=self.img_shape)
# Translate images to the other domain
fake_B = self.g_A2B(img_A)
fake_A = self.g_B2A(img_B)
# Translate images back to original domain
reconstr_A = self.g_B2A(fake_B)
reconstr_B = self.g_A2B(fake_A)
# Identity mapping of images
img_A_id_truth = self.g_B2A(img_A)
img_B_id_truth = self.g_A2B(img_B)
# For the combined model we will only train the generators
self.d_A.trainable = False
self.d_B.trainable = False
# Discriminators determines validity of translated images
valid_A = self.d_A(fake_A)
valid_B = self.d_B(fake_B)
# Combined model trains generators to fool discriminators
self.combined = Model(inputs=[img_A, img_B],
outputs=[ valid_A, valid_B,
reconstr_A, reconstr_B,
img_A_id_truth, img_B_id_truth ])
self.combined.compile(loss=['mse', 'mse',
'mae', 'mae',
'mae', 'mae'],
loss_weights=[ 1, 1,
self.lambda_cycle, self.lambda_cycle,
self.lambda_id, self.lambda_id ],
optimizer=optimizer)
def build_generator(self):
"""U-Net Generator"""
def conv2d(layer_input, filters, f_size=3):
"""Layers used during downsampling"""
d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
d = Activation("relu")(d)#ReLU(alpha=0.2)(d)
d = InstanceNormalization()(d)
return d
def deconv2d(layer_input, skip_input, filters, f_size=4, dropout_rate=0.2):
"""Layers used during upsampling"""
u = UpSampling2D(size=2)(layer_input)
u = Conv2D(filters, kernel_size=f_size, strides=1, padding='same', activation='relu')(u)
if dropout_rate:
u = Dropout(dropout_rate)(u)
u = InstanceNormalization()(u)
u = Concatenate()([u, skip_input])
return u
# Image input
d0 = Input(shape=self.img_shape)
# Downsampling
d1 = conv2d(d0, self.gf)
d2 = conv2d(d1, self.gf*2)
d3 = conv2d(d2, self.gf*4)
# Upsampling
u1 = deconv2d(d3, d2, self.gf*4)
u2 = deconv2d(u1, d1, self.gf*2)
u4 = UpSampling2D(size=2)(u2)
output_img = Conv2D(self.channels, kernel_size=4, strides=1, padding='same', activation='relu')(u4)
model=Model(d0, output_img)
model.summary
return model
def build_discriminator(self):
def d_layer(layer_input, filters, f_size=4, normalization=True):
"""Discriminator layer"""
d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
d = Activation("relu")(d)#LeakyReLU(alpha=0.2)(d)
if normalization:
d = InstanceNormalization()(d)
return d
img = Input(shape=self.img_shape)
d1 = d_layer(img, self.df, normalization=True)
d2 = d_layer(d1, self.df*2)
d3 = d_layer(d2, self.df*4)
d4 = d_layer(d3, self.df*8)
validity = Conv2D(1, kernel_size=4, strides=1, padding='same')(d4)
return Model(img, validity)
def train(self,dataset,X_train,X_true,time,lat,lon,epochs,batch_size=1, sample_interval=50):
start_time = datetime.datetime.now()
# Adversarial loss ground truths
for epoch in range(epochs):
for batch_i, (imgs_A, imgs_B) in enumerate(dataset.shuffle(len(dataset)).batch(batch_size)):
valid = np.ones((imgs_A.shape[0],3,3,1))
fake = np.zeros((imgs_A.shape[0],3,3,1))
imgs_A = np.expand_dims(imgs_A, axis=3)
imgs_B=np.expand_dims(imgs_B, axis=3)
fake_B = self.g_A2B.predict(imgs_A)
fake_A = self.g_B2A.predict(imgs_B)
# Train the discriminators (original images = real / translated = Fake)
dA_loss_real = self.d_A.train_on_batch(imgs_A, valid)
dA_loss_fake = self.d_A.train_on_batch(fake_A, fake)
dA_loss = 0.5 * np.add(dA_loss_real, dA_loss_fake)
dB_loss_real = self.d_B.train_on_batch(imgs_B, valid)
dB_loss_fake = self.d_B.train_on_batch(fake_B, fake)
dB_loss = 0.5 * np.add(dB_loss_real, dB_loss_fake)
d_loss = 0.5 * np.add(dA_loss, dB_loss)
g_loss = self.combined.train_on_batch([imgs_A, imgs_B],
[valid, valid,
imgs_A, imgs_B,
imgs_A, imgs_B])
elapsed_time = datetime.datetime.now() - start_time
del valid,fake
if batch_i % 20 == 0:
print ("[Epoch %d/%d] [Batch %d/%d] [D loss: %f, acc: %3d%%] [G loss: %05f, adv: %05f, recon: %05f, id: %05f] time: %s " \
% ( epoch, epochs,
batch_i, len(dataset)//batch_size,
d_loss[0], 100*d_loss[1],
g_loss[0],
np.mean(g_loss[1:3]),
np.mean(g_loss[3:5]),
np.mean(g_loss[5:6]),
elapsed_time))
if epoch % sample_interval == 0:
self.sample_images(epoch,X_train,X_true,time,lat,lon)
def sample_images(self, epoch,X_train,X_true,time,lat,lon):
r, c = 4, 4
idx = np.random.randint(0, X_train.shape[0], r)
imgs_A= X_train[idx]
imgs_B=X_true[idx]
time=time[idx]
imgs_A = np.expand_dims(imgs_A, axis=3)
imgs_B=np.expand_dims(imgs_B, axis=3)
# Translate images to the other domain
fake_B = self.g_A2B.predict(imgs_A)
fig, axs = plt.subplots(r, c,figsize=(12,8),constrained_layout=True)
for i in range(r):
axs[i,0].contourf(lon,lat,imgs_A[i,:,:,0],cmap='RdBu_r')
axs[i,1].contourf(lon,lat,fake_B[i,:,:,0],cmap='RdBu_r')
axs[i,2].contourf(lon,lat,imgs_B[i,:,:,0],cmap='RdBu_r')
ax3=axs[i,3].contourf(lon,lat,imgs_B[i,:,:,0]-fake_B[i,:,:,0],levels=5,cmap='RdBu_r')
fig.colorbar(ax3,ax=axs[i,3])
axs[i,0].set_title(str(time[i].values).split("T")[0])
axs[i,1].set_title("Translated")
axs[i,2].set_title("obs")
axs[i,3].set_title("difference_%04f" % np.sqrt(np.mean((imgs_B[i,:,:,0]-fake_B[i,:,:,0])**2)))
fig.savefig("../figure/cycle/wpsh_%d.png" % epoch)
plt.close()
if __name__ == '__main__':
# profiler.warmup()
# profiler.start(logdir='./logdir')
keras.backend.clear_session()
cgan =CycleGAN()
cgan.train(train_dataset,train_x,train_y,time_date,
lat,lon,epochs=2000,batch_size=128, sample_interval=100)
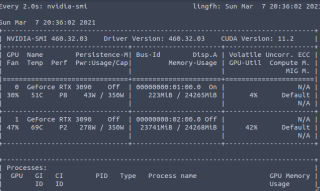
这时我模仿论坛里面,写的Cycle GAN的网络模型,自建训练过程和论坛大佬的基本一致,除了自己构建的数据集。现在问题在于每当我跑一定的epoch数后,程序就会自动被杀死,并且没有任何报错,终端运行提示被杀死,jupyter 运行,直接kernel restart 。并且都没有对应报错。所以我怀疑有可能是内存溢出?还是可能我cuda等配置不匹配?我电脑配置为两张RTX3090(但只用了一张训练,实际显存24268MIB),Ubuntu20.04 ,cuda11.0(将cuda11.1的ptxas替换了11.0的),tensorflow2.4 ,数据量大概是(10936,40,40)。求各位大佬帮帮忙