现在有一个表格a,里面有client_id(用户id)、starttime(用户登录时间)、age(用户年龄)
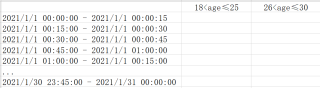
求问我想知道在时间2021-01-01 到 2021-01-30 中每隔15分钟的时间内,年龄为18-25,26-30岁的人的登录人数,得到的目标表结构大概是这样,请问这要怎么做呢?感觉学了不少但是碰到这种多维的分析就不知如何下手。。

现在有一个表格a,里面有client_id(用户id)、starttime(用户登录时间)、age(用户年龄)
求问我想知道在时间2021-01-01 到 2021-01-30 中每隔15分钟的时间内,年龄为18-25,26-30岁的人的登录人数,得到的目标表结构大概是这样,请问这要怎么做呢?感觉学了不少但是碰到这种多维的分析就不知如何下手。。
 分享
分享
这个统计主要涉及两个问题吧:
1. 是分年龄段统计,这个比较好解决,直接在聚合函数中加上CASE WHEN 条件就可以,比如统计18至25岁的用户数就是这样:
count(DISTINCT CASE WHEN age>=18 AND age<=25 THEN client_id END) AS uv_18_25
2. 是按15分钟聚合,这个稍微复杂些,我的思路是先把时间字段转成 unix时间戳,时间戳除以900取整再乘以900就可以取到每隔15分钟的时间,然后再格式化下时间戳,按时间段GROUP BY就可以:
FROM_UNIXTIME((UNIX_TIMESTAMP(starttime) DIV 900)*900, '%Y-%m-%d %H:%i:%s') 这是每隔15分钟的时间
FROM_UNIXTIME((UNIX_TIMESTAMP(starttime) DIV 900)*900 + 900, '%Y-%m-%d %H:%i:%s') 这是在前面的时间上再加上15分钟的时间
最后SQL写成这样,可供参考:
SELECT CONCAT(
FROM_UNIXTIME((UNIX_TIMESTAMP(starttime) DIV 900)*900, '%Y-%m-%d %H:%i:%s'),
' - ',
FROM_UNIXTIME((UNIX_TIMESTAMP(starttime) DIV 900)*900 + 900, '%Y-%m-%d %H:%i:%s')
) AS t1 ,
count(DISTINCT CASE WHEN age>=18
AND age<=25 THEN client_id END) AS uv_18_25 ,
count(DISTINCT CASE WHEN age>=26
AND age<=30 THEN client_id END) AS uv_26_30
FROM tb_a
WHERE starttime BETWEEN '2021-01-01 00:00' AND '2021-01-01 01:00'
GROUP BY CONCAT(
FROM_UNIXTIME((UNIX_TIMESTAMP(starttime) DIV 900)*900, '%Y-%m-%d %H:%i:%s'),
' - ',
FROM_UNIXTIME((UNIX_TIMESTAMP(starttime) DIV 900)*900 + 900, '%Y-%m-%d %H:%i:%s')
)
;
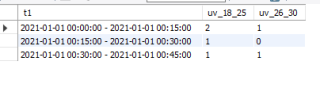
构造了几条数据,结果是这样的:
分享



