python入坑两周小萌新,在跟视频练习时,发现对应的正则方法好像无法使用,但是在CSDN上面参考了几个好像也没发现有什么问题。
但是:results = 【】 ,这是什么原因呢?
请大佬指教:
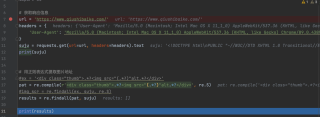

python入坑两周小萌新,在跟视频练习时,发现对应的正则方法好像无法使用,但是在CSDN上面参考了几个好像也没发现有什么问题。
但是:results = 【】 ,这是什么原因呢?
请大佬指教:
 分享
分享
正则表达式在不同的网站上不是通用的,我看了下糗事百科那个网址,没有符合你那个正则的文本。你可以具体描述下你要做些什么。
分享



